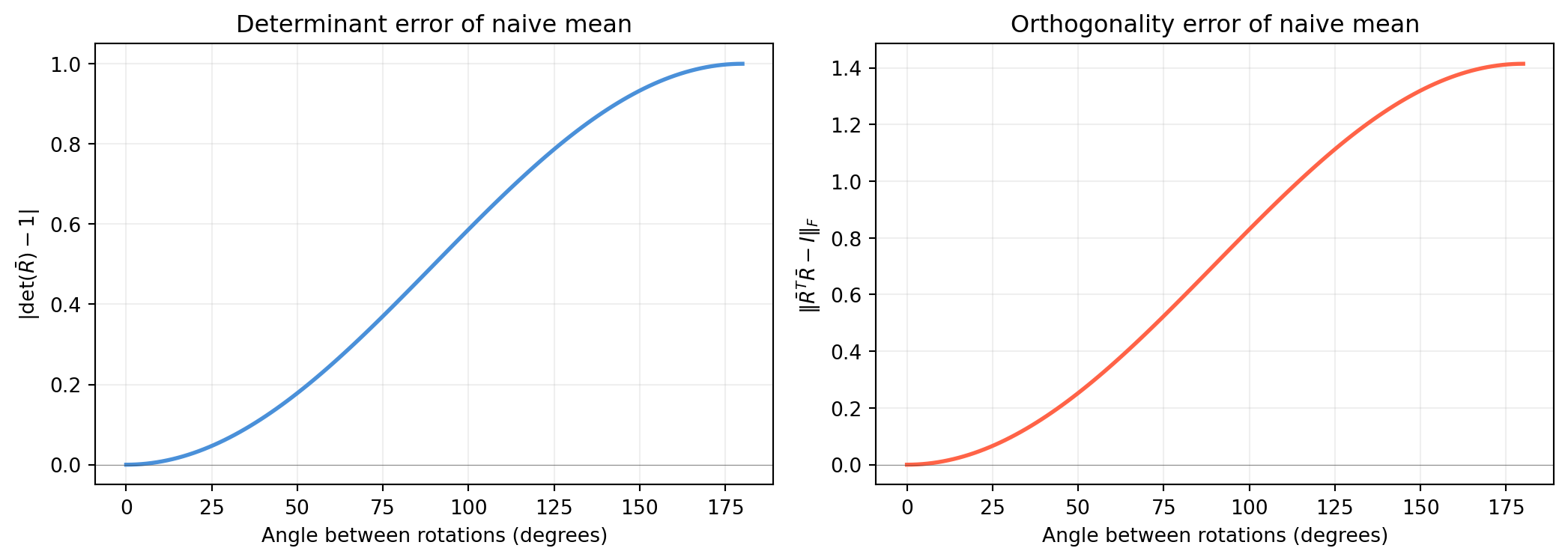
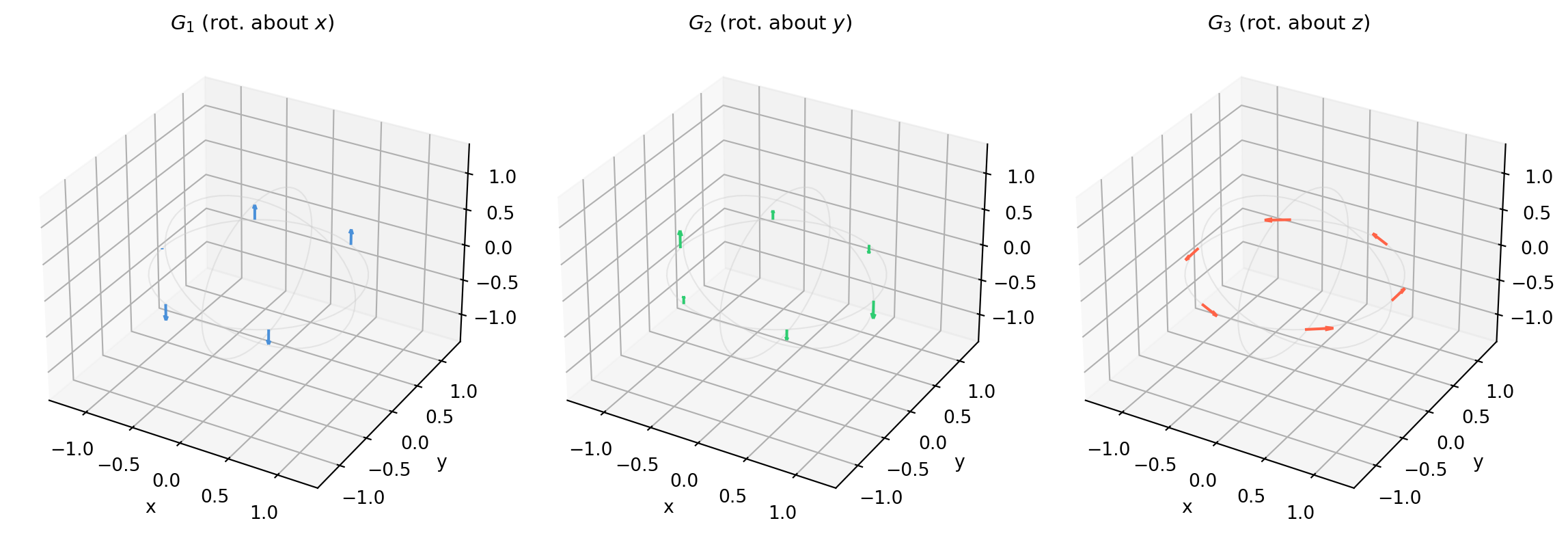
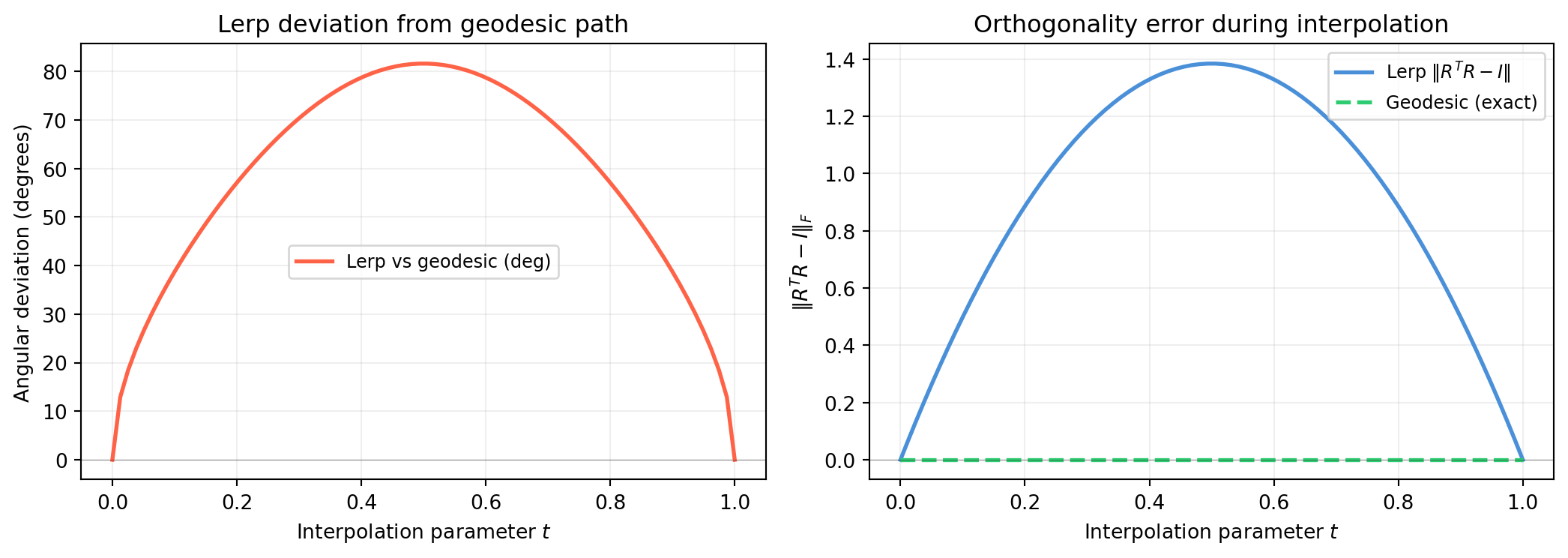
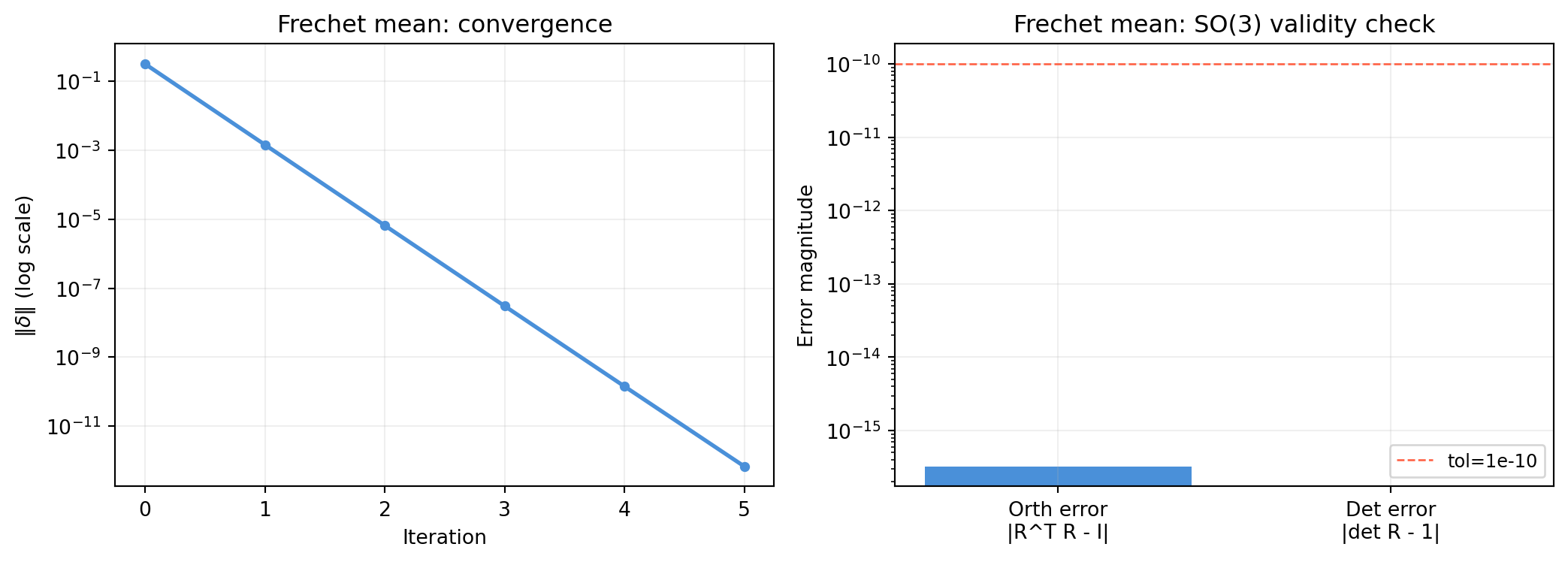
import numpy as np
import matplotlib.pyplot as plt
from scipy.linalg import expm, logm
from scipy.spatial.transform import Rotation
def hat3(w):
w = np.asarray(w, dtype=float)
return np.array([[ 0.0, -w[2], w[1]],
[ w[2], 0.0, -w[0]],
[-w[1], w[0], 0.0]])
def hat6(xi):
Xi = np.zeros((4, 4))
Xi[:3, :3] = hat3(xi[3:])
Xi[:3, 3] = xi[:3]
return Xi # shape (4, 4)
def vee6(Xi):
return np.concatenate([Xi[:3, 3], [Xi[2,1], Xi[0,2], Xi[1,0]]])
rng = np.random.default_rng(7)
N = 10
# Ground truth: 10 poses on a circle in 2D (z=0, rotation about z)
angles_gt = np.linspace(0, 2 * np.pi * 9 / 10, N) # shape (10,)
T_gt = []
for a in angles_gt:
R = Rotation.from_euler('z', a).as_matrix() # shape (3, 3)
t = np.array([np.cos(a) * 3, np.sin(a) * 3, 0.0]) # shape (3,)
T = np.eye(4)
T[:3, :3] = R; T[:3, 3] = t
T_gt.append(T)
# Noisy relative measurements between consecutive poses
sigma_t, sigma_r = 0.05, 0.03 # translation / rotation noise
edges = [(i, (i + 1) % N) for i in range(N)]
measurements = {}
for i, j in edges:
T_rel = np.linalg.inv(T_gt[i]) @ T_gt[j] # shape (4, 4)
noise = np.zeros(6)
noise[:3] = rng.normal(0, sigma_t, 3)
noise[3:] = rng.normal(0, sigma_r, 3)
T_rel_noisy = T_rel @ expm(hat6(noise))
measurements[(i, j)] = T_rel_noisy
# Simple Riemannian GD (gradient w.r.t. se(3) perturbation, fixed step)
T_est = [T_gt[0].copy()] + [np.eye(4) for _ in range(N - 1)]
# Initialize from chained noisy measurements
for k in range(1, N):
T_est[k] = T_est[k - 1] @ measurements[(k - 1, k)]
step = 0.3
for _ in range(80):
grads = [np.zeros(6) for _ in range(N)]
for (i, j), T_ij in measurements.items():
err_mat = np.linalg.inv(T_est[i]) @ T_est[j] @ np.linalg.inv(T_ij)
xi_err = vee6(logm(err_mat).real) # shape (6,)
grads[i] -= xi_err
grads[j] += xi_err
for k in range(1, N): # keep T_est[0] fixed as anchor
T_est[k] = T_est[k] @ expm(hat6(-step * grads[k]))
# Plot
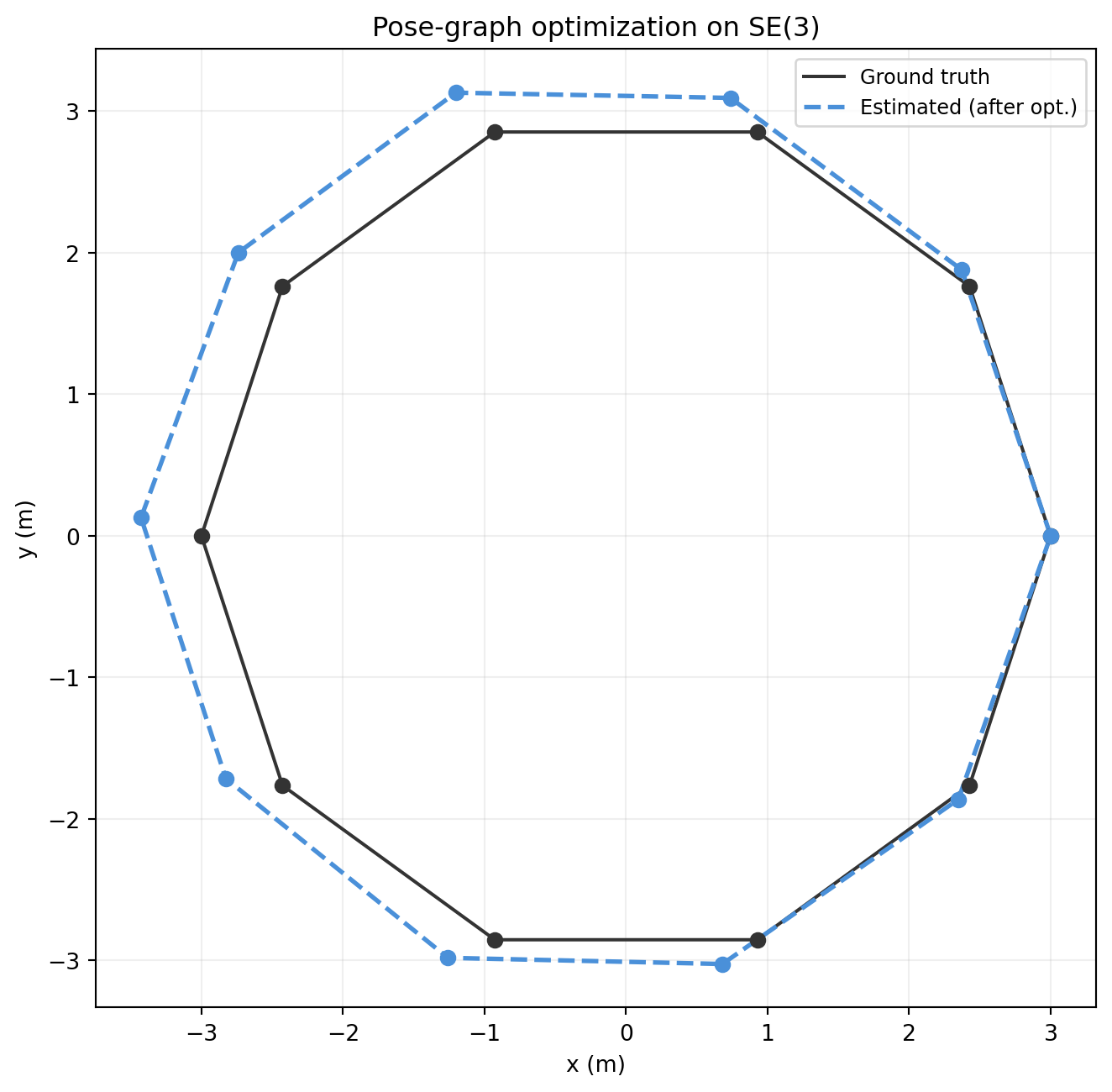
fig, ax = plt.subplots(figsize=(7, 7))
pts_gt = np.array([T[:3, 3] for T in T_gt]) # shape (10, 3)
pts_est = np.array([T[:3, 3] for T in T_est]) # shape (10, 3)
ax.plot(np.append(pts_gt[:, 0], pts_gt[0, 0]),
np.append(pts_gt[:, 1], pts_gt[0, 1]),
color='#333333', lw=1.5, label='Ground truth')
ax.scatter(pts_gt[:, 0], pts_gt[:, 1], color='#333333', s=40, zorder=3)
ax.plot(np.append(pts_est[:, 0], pts_est[0, 0]),
np.append(pts_est[:, 1], pts_est[0, 1]),
color='#4a90d9', lw=2, linestyle='--', label='Estimated (after opt.)')
ax.scatter(pts_est[:, 0], pts_est[:, 1], color='#4a90d9', s=40, zorder=3)
ax.set_aspect('equal')
ax.set_xlabel('x (m)'); ax.set_ylabel('y (m)')
ax.set_title('Pose-graph optimization on SE(3)')
ax.legend(fontsize=9)
ax.grid(alpha=0.2)
plt.tight_layout()
plt.show()
# Error metrics
pos_errs = np.linalg.norm(pts_gt - pts_est, axis=1) # shape (10,)
print(f"Mean position error after optimization: {pos_errs.mean():.4f} m")
print(f"Max position error after optimization: {pos_errs.max():.4f} m")