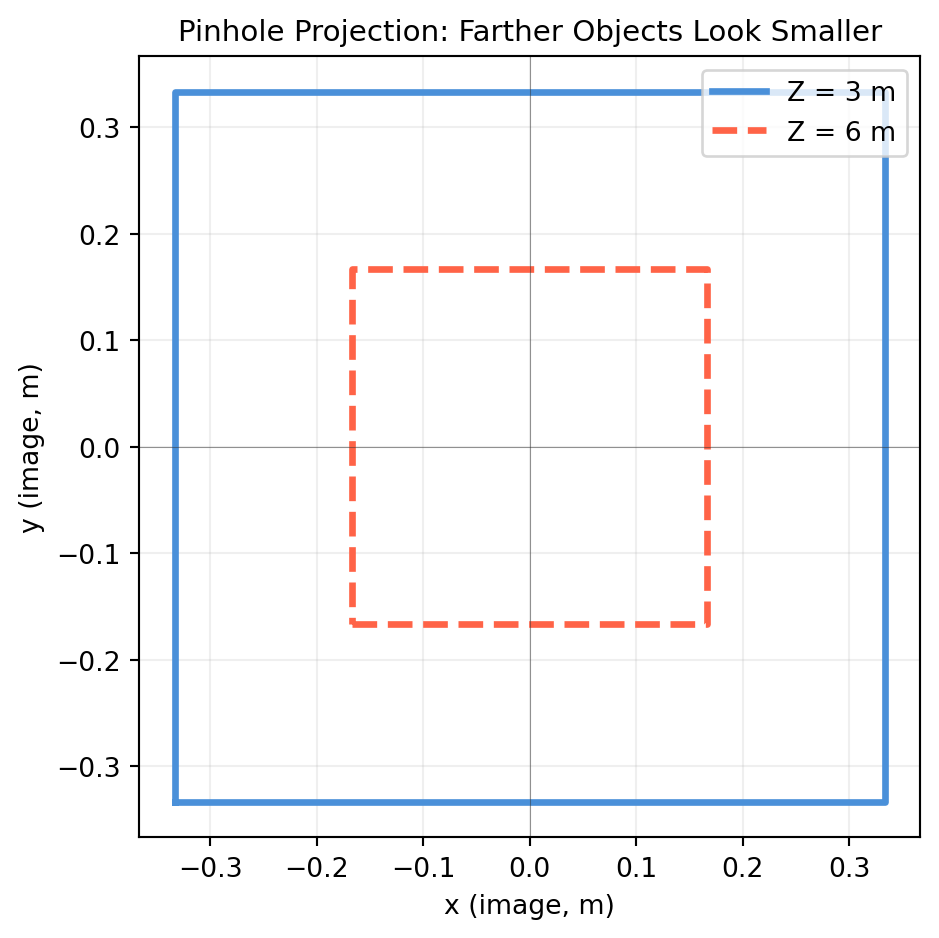
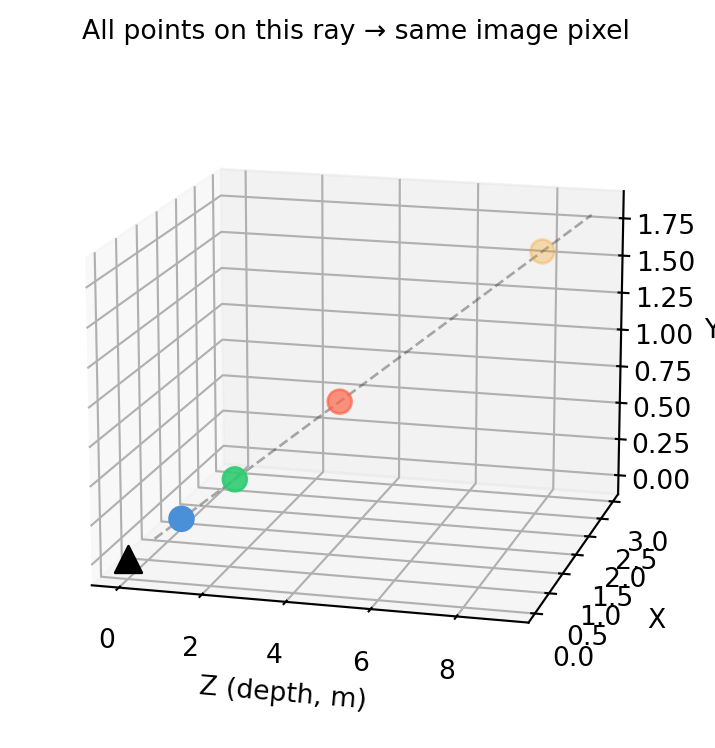
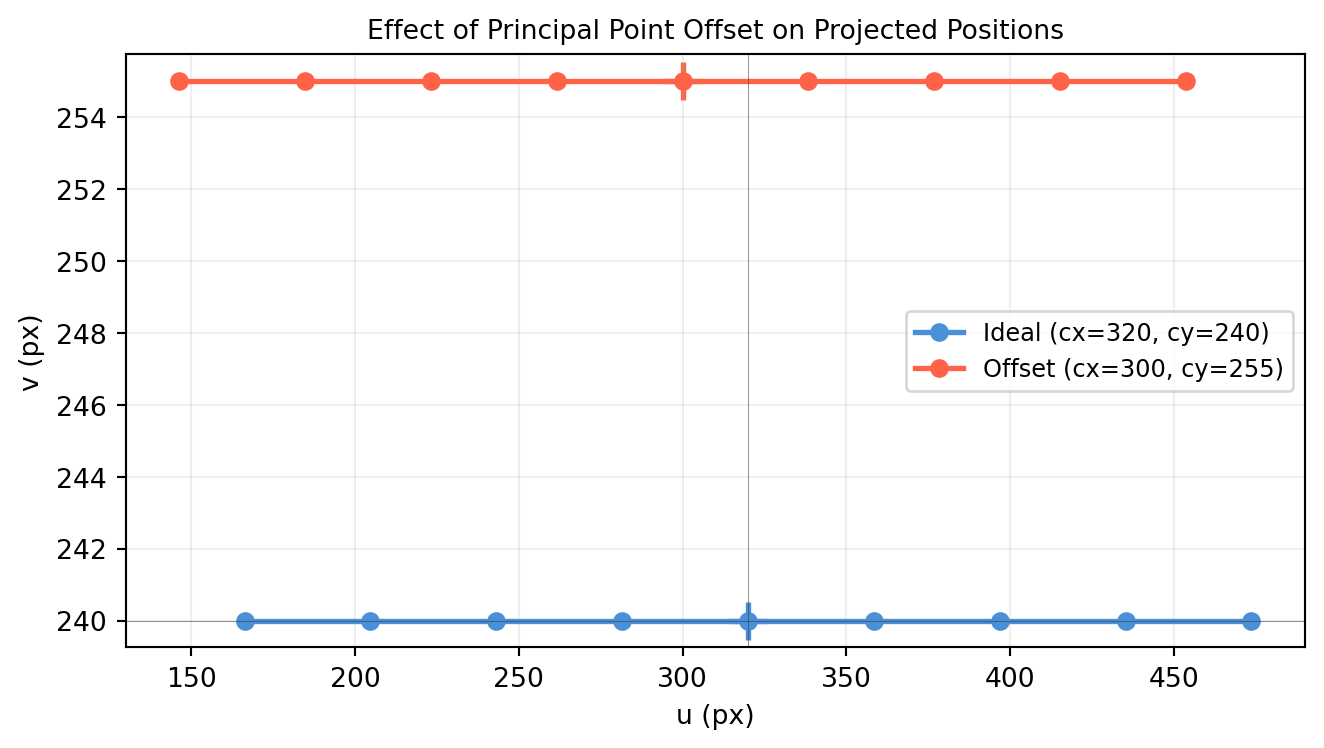
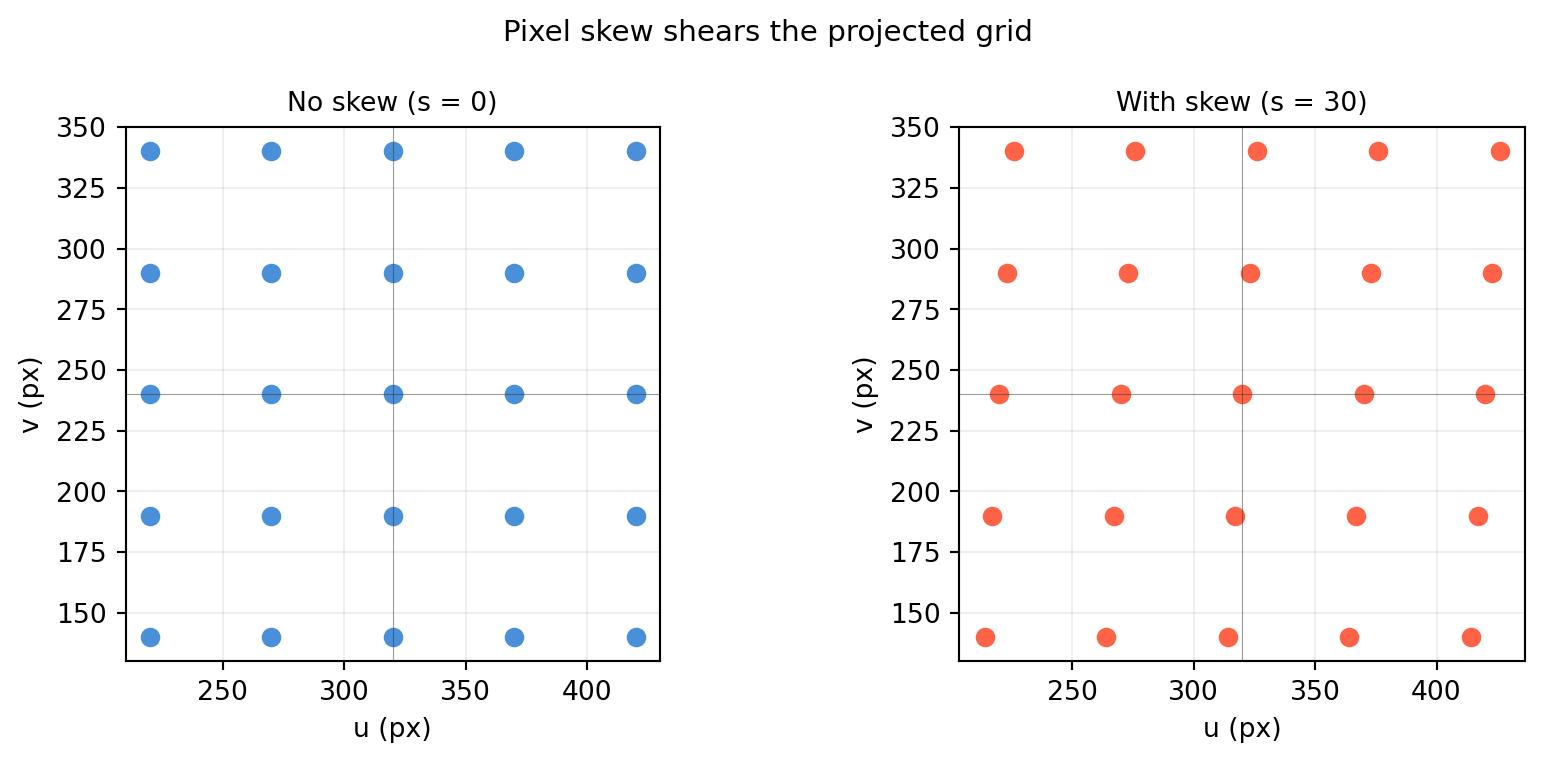
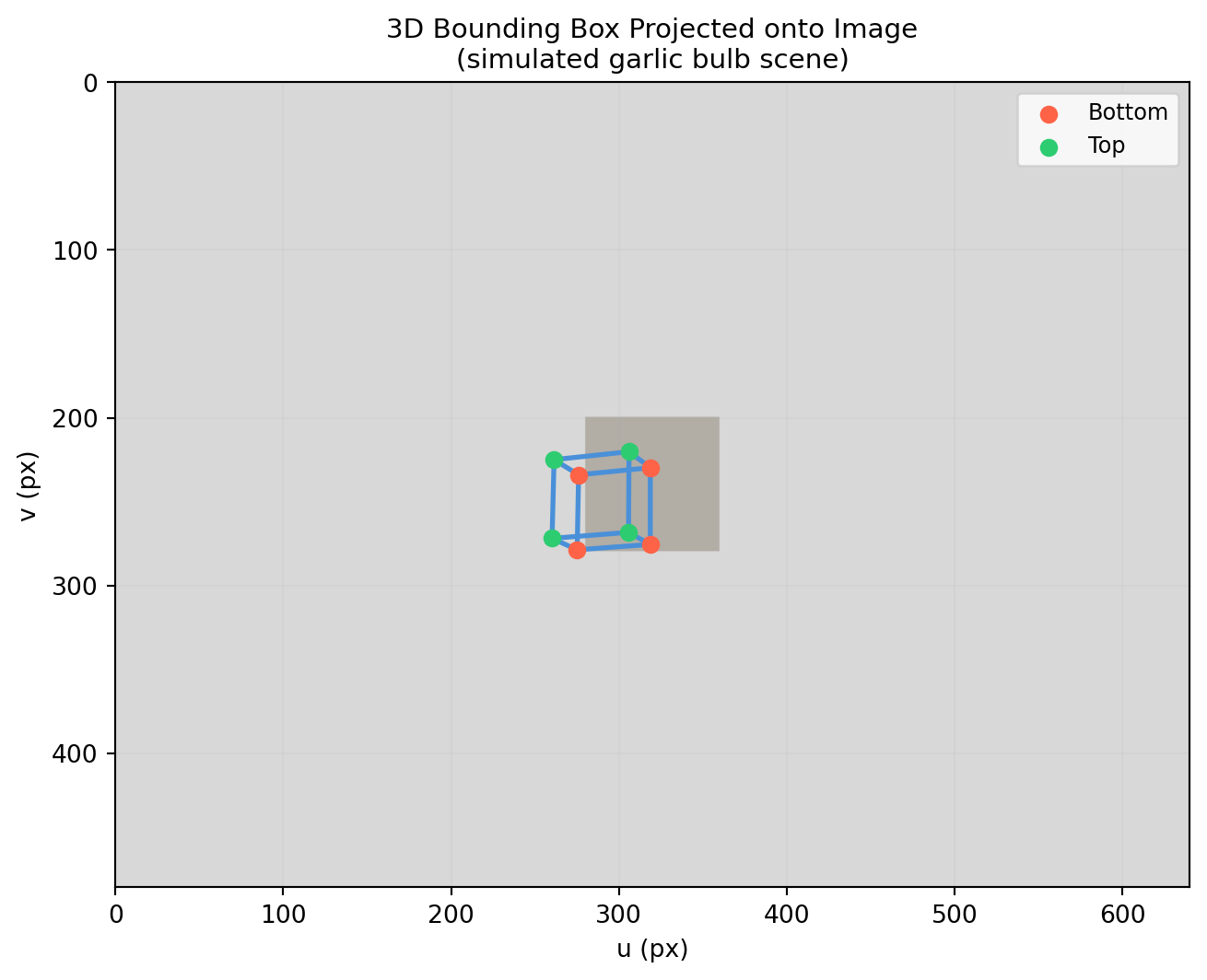
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
def make_T(R, t):
T = np.eye(4); T[:3,:3] = R; T[:3,3] = t
return T # shape (4, 4)
def Ry(b):
c,s=np.cos(b),np.sin(b)
return np.array([[c,0.,s],[0.,1.,0.],[-s,0.,c]])
def Rx(a):
c,s=np.cos(a),np.sin(a)
return np.array([[1.,0.,0.],[0.,c,-s],[0.,s,c]])
# Camera intrinsics (RealSense D435i approximate)
K = np.array([[615., 0., 320.],
[ 0., 615., 240.],
[ 0., 0., 1.]]) # shape (3, 3)
# Camera extrinsic: camera at (0, -0.5, 2) in world, looking forward+down
cam_pos = np.array([0., -0.5, 2.0])
R_cam = Rx(np.deg2rad(-15.))
t_ext = -R_cam @ cam_pos
Rt = np.column_stack([R_cam, t_ext]) # shape (3, 4)
P = K @ Rt # shape (3, 4) — full projection matrix
# Bounding box in object frame (a garlic bulb: roughly 8cm × 8cm × 6cm)
lx, ly, lz = 0.08, 0.08, 0.06 # half-sizes in metres
corners_obj = np.array([
[-lx,-ly,-lz], [ lx,-ly,-lz], [ lx, ly,-lz], [-lx, ly,-lz], # bottom
[-lx,-ly, lz], [ lx,-ly, lz], [ lx, ly, lz], [-lx, ly, lz], # top
], dtype=float) # shape (8, 3)
# Object pose in world: centre at (0.1, 0, 0), rotated 20° about y
T_WO = make_T(Ry(np.deg2rad(20.)), np.array([0.1, 0., 0.])) # shape (4, 4)
# Transform box corners: object → world → image
corners_w_h = (T_WO @ np.column_stack([corners_obj, np.ones(8)]).T).T # shape (8, 4)
proj = (P @ corners_w_h.T).T # shape (8, 3)
uvs = proj[:, :2] / proj[:, 2:3] # shape (8, 2)
# Box edges: bottom face, top face, vertical pillars
edges = [(0,1),(1,2),(2,3),(3,0), # bottom
(4,5),(5,6),(6,7),(7,4), # top
(0,4),(1,5),(2,6),(3,7)] # pillars
# Simulated background image (grey gradient)
img = np.ones((480, 640, 3)) * 0.85 # light grey
img[200:280, 280:360] = [0.7, 0.68, 0.65] # rough garlic blob
fig, ax = plt.subplots(figsize=(7, 5.5))
ax.imshow(img, origin='upper', extent=[0, 640, 480, 0])
for i, j in edges:
ax.plot([uvs[i,0], uvs[j,0]], [uvs[i,1], uvs[j,1]],
color='#4a90d9', lw=2.)
ax.scatter(uvs[:4, 0], uvs[:4, 1], color='tomato', s=40, zorder=5, label='Bottom')
ax.scatter(uvs[4:, 0], uvs[4:, 1], color='#2ecc71', s=40, zorder=5, label='Top')
ax.set_xlim(0, 640); ax.set_ylim(480, 0)
ax.set_title('3D Bounding Box Projected onto Image\n(simulated garlic bulb scene)', fontsize=11)
ax.set_xlabel('u (px)'); ax.set_ylabel('v (px)')
ax.legend(fontsize=9, loc='upper right')
ax.grid(True, alpha=0.1)
plt.tight_layout()
plt.show()