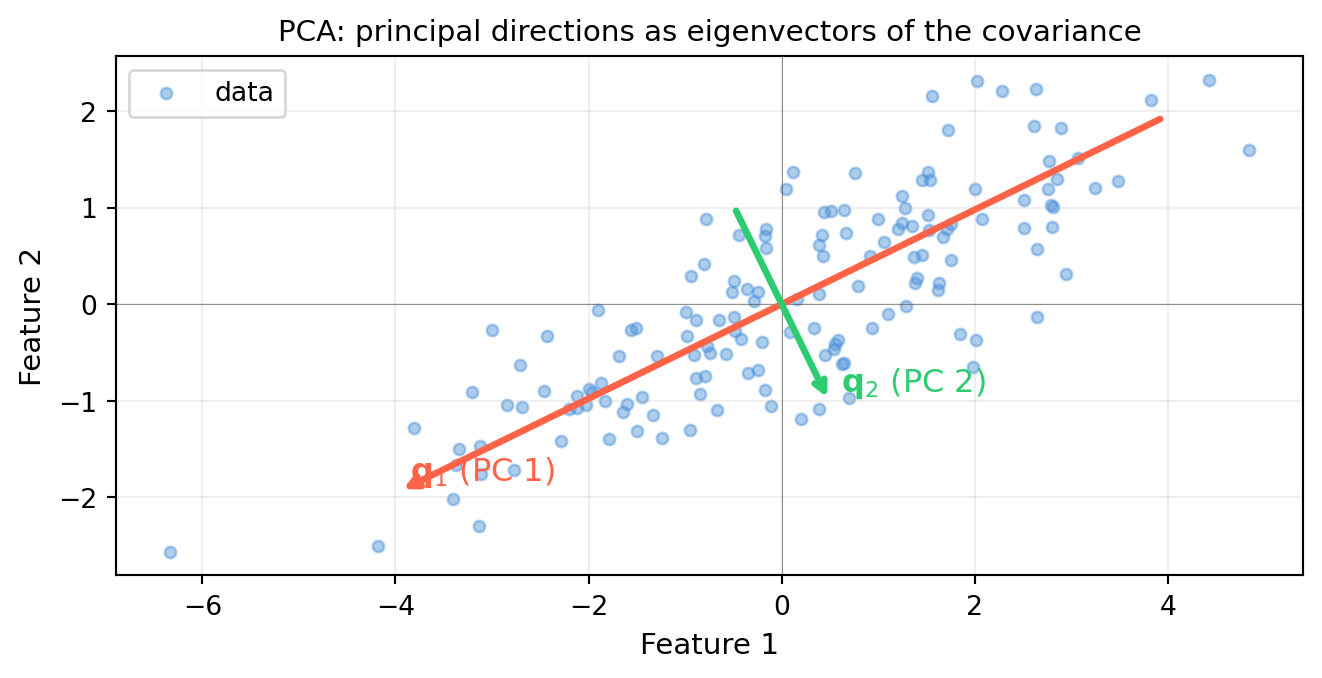
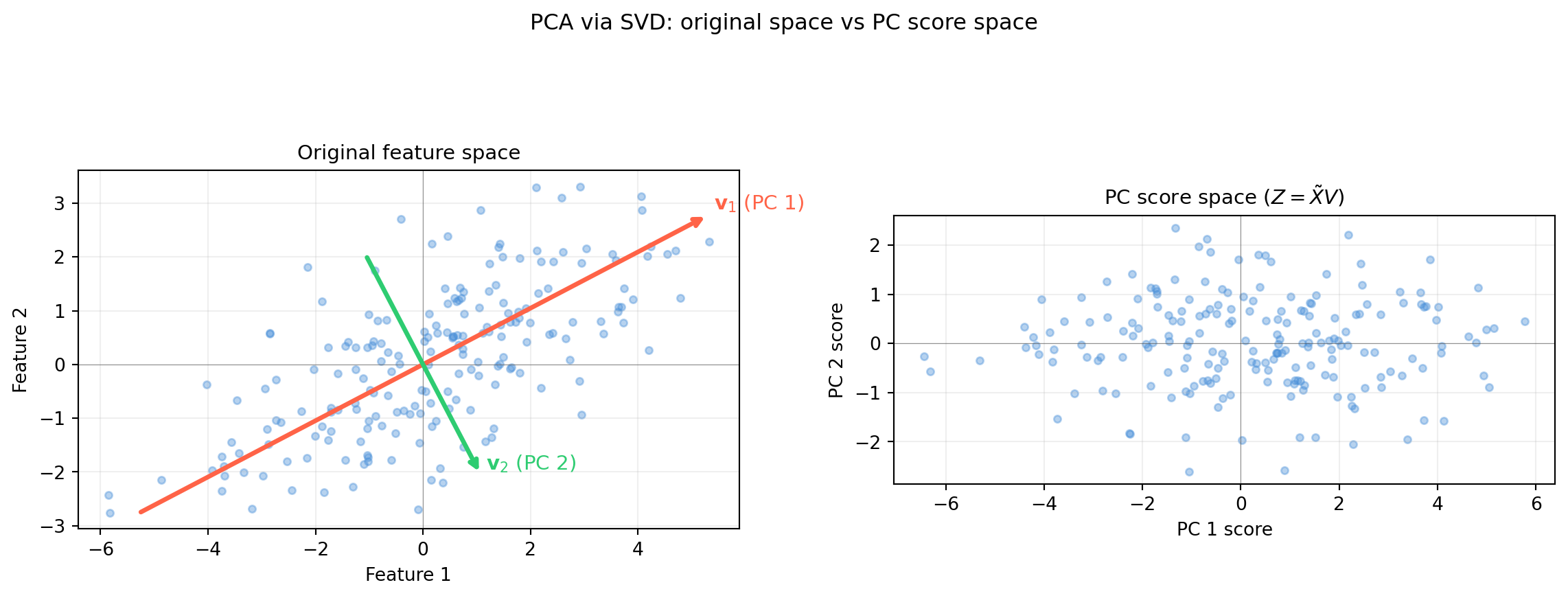
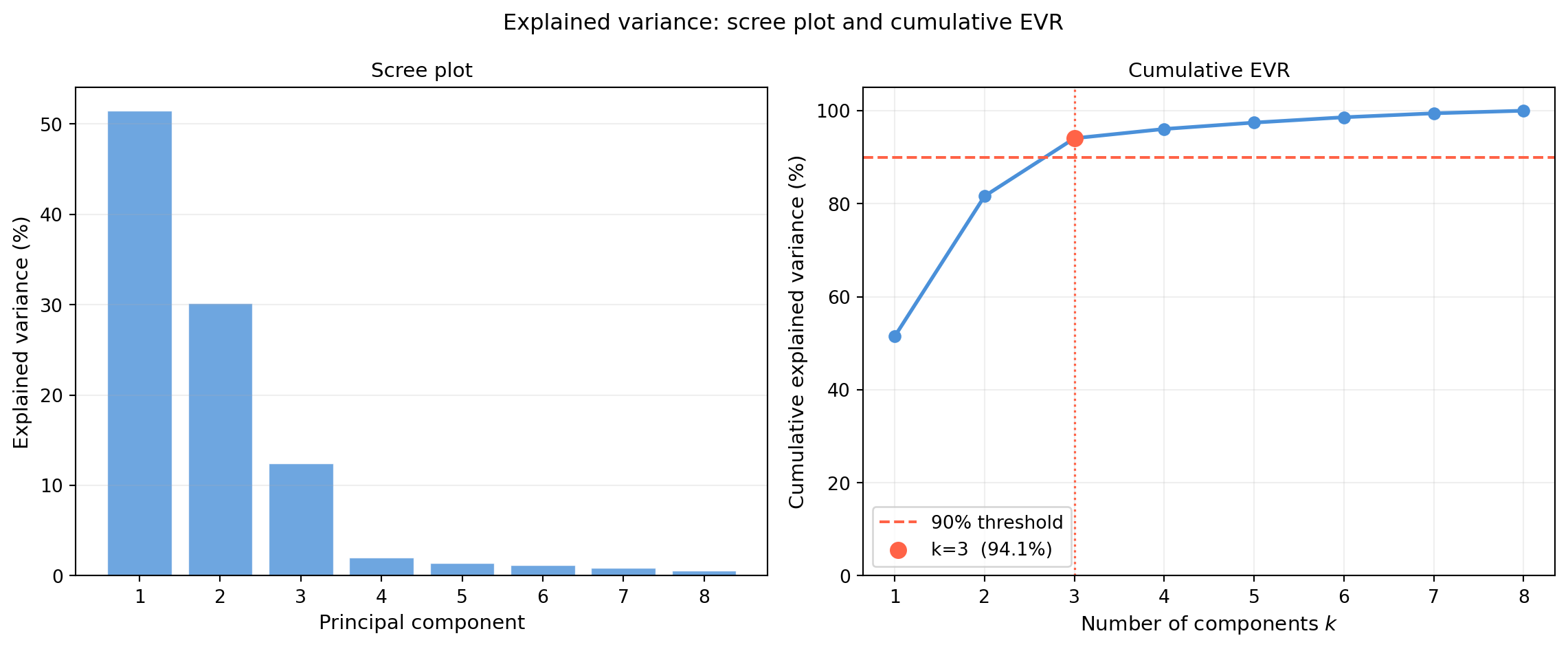
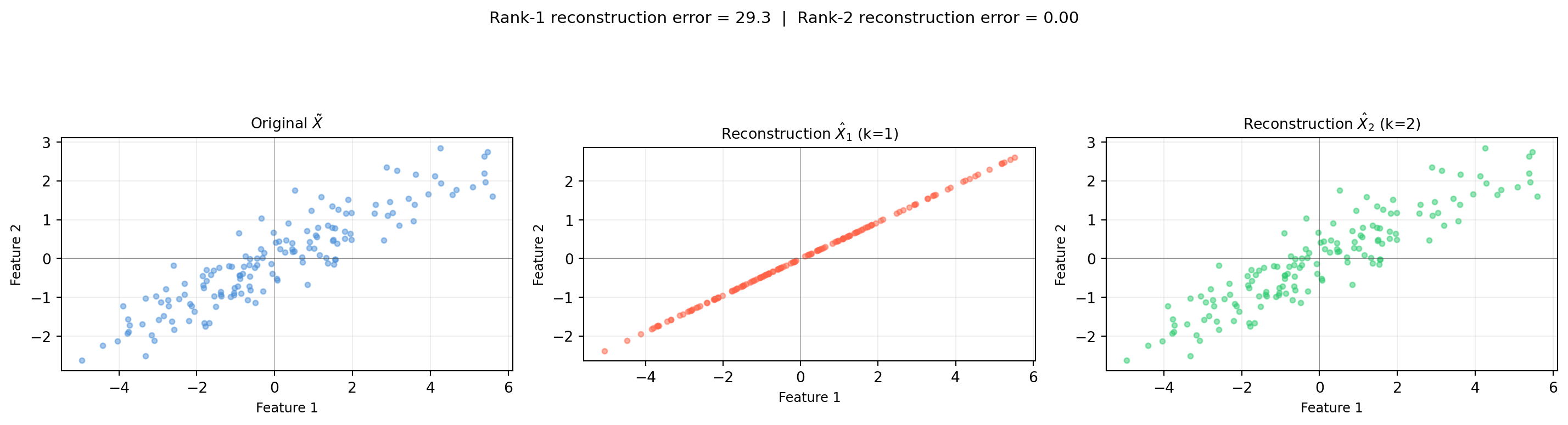
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(208)
# Re-generate (self-contained)
mu_good = np.array([320.0, 85.0, 3.8, 180.0, 0.05])
Sigma_good = np.array([
[400.0, 60.0, 3.5, -20.0, 0.0],
[ 60.0, 40.0, 0.8, -8.0, 0.0],
[ 3.5, 0.8, 0.08, -0.5, 0.0],
[-20.0, -8.0, -0.5, 600.0, 0.0],
[ 0.0, 0.0, 0.0, 0.0, 0.005]
])
n_good = 500
L_good = np.linalg.cholesky(Sigma_good)
X_good = rng.standard_normal((n_good, 5)) @ L_good.T + mu_good
X_good[:, 4] = np.clip(X_good[:, 4], 0, 1)
defs = {
'Chalky': (np.array([300.0, 83.0, 3.6, 195.0, 0.45]),
np.diag([300.0, 35.0, 0.06, 400.0, 0.003]), 60),
'Broken': (np.array([160.0, 78.0, 2.1, 175.0, 0.08]),
np.diag([200.0, 50.0, 0.05, 500.0, 0.002]), 50),
'Discolored': (np.array([315.0, 84.0, 3.75, 115.0, 0.06]),
np.diag([350.0, 38.0, 0.07, 300.0, 0.002]), 50),
}
X_def = {}
for name, (mu_d, Sig_d, n_d) in defs.items():
Xd = rng.standard_normal((n_d, 5)) @ np.linalg.cholesky(Sig_d).T + mu_d
Xd[:, 4] = np.clip(Xd[:, 4], 0, 1)
X_def[name] = Xd
mu_hat = X_good.mean(axis=0)
std_hat = X_good.std(axis=0, ddof=1)
def standardize(X, mu, std):
return (X - mu) / std
X_good_s = standardize(X_good, mu_hat, std_hat)
_, s, Vt = np.linalg.svd(X_good_s, full_matrices=False)
V = Vt.T
def project(X, mu, std, V, k=2):
return standardize(X, mu, std) @ V[:, :k]
def recon_error(X, mu, std, V, k=2):
Xs = standardize(X, mu, std)
return np.linalg.norm(Xs - Xs @ V[:, :k] @ V[:, :k].T, axis=1)
Z_good = project(X_good, mu_hat, std_hat, V)
err_good = recon_error(X_good, mu_hat, std_hat, V)
tau = np.percentile(err_good, 99)
def_colors = {'Chalky': 'tomato', 'Broken': '#e67e22', 'Discolored': '#9b59b6'}
def_markers = {'Chalky': '^', 'Broken': 's', 'Discolored': 'D'}
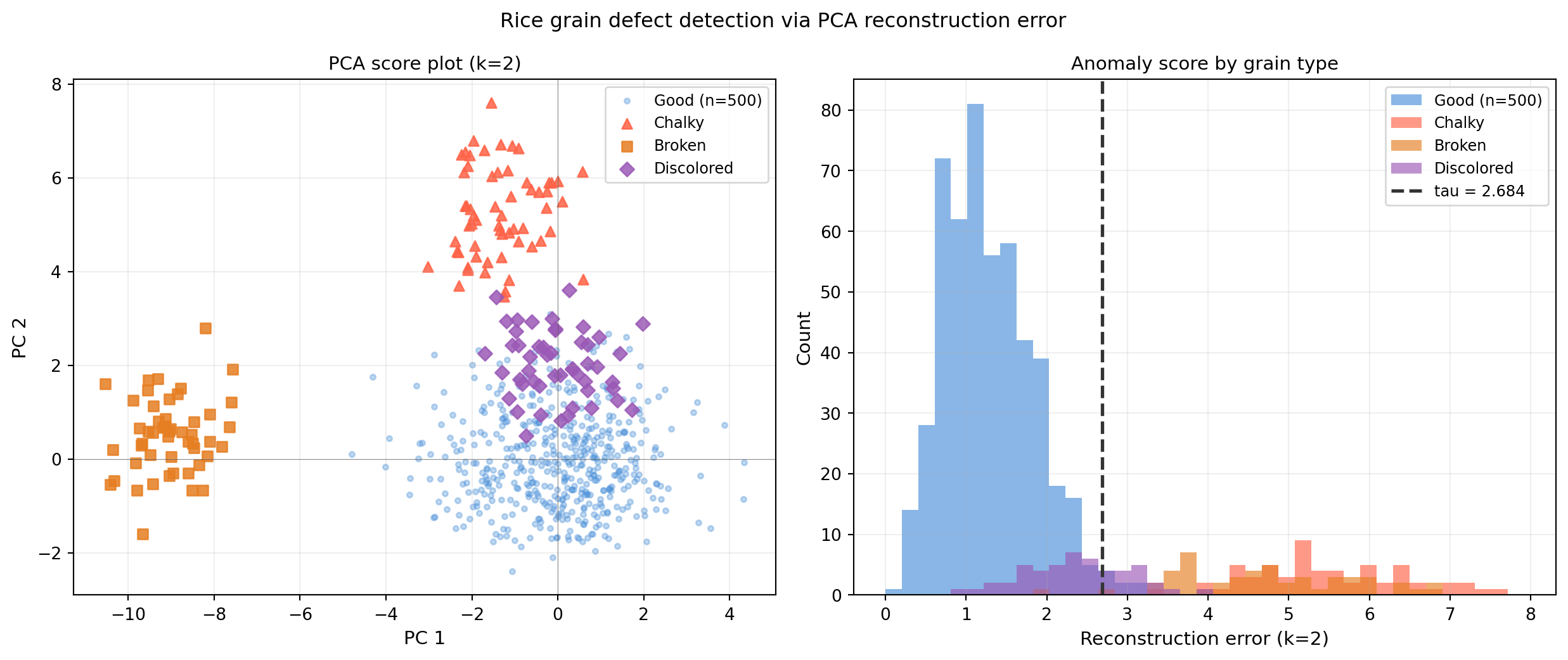
fig, axes = plt.subplots(1, 2, figsize=(13, 5.5))
# Left: PCA score plot (PC1 vs PC2)
ax = axes[0]
ax.scatter(Z_good[:, 0], Z_good[:, 1], s=10, color='#4a90d9', alpha=0.35,
label=f'Good (n={n_good})')
for name, Xd in X_def.items():
Zd = project(Xd, mu_hat, std_hat, V)
ax.scatter(Zd[:, 0], Zd[:, 1], s=35, color=def_colors[name],
alpha=0.85, marker=def_markers[name], label=name)
ax.axhline(0, color='#333333', lw=0.4, alpha=0.5)
ax.axvline(0, color='#333333', lw=0.4, alpha=0.5)
ax.set_xlabel('PC 1', fontsize=11)
ax.set_ylabel('PC 2', fontsize=11)
ax.set_title('PCA score plot (k=2)', fontsize=11)
ax.legend(fontsize=9)
ax.grid(alpha=0.2)
# Right: reconstruction error histogram
ax2 = axes[1]
all_err = np.concatenate([err_good]
+ [recon_error(X_def[n], mu_hat, std_hat, V) for n in def_colors])
bins = np.linspace(0, max(all_err) * 1.05, 40)
ax2.hist(err_good, bins=bins, color='#4a90d9', alpha=0.65, label=f'Good (n={n_good})')
for name, Xd in X_def.items():
ax2.hist(recon_error(Xd, mu_hat, std_hat, V),
bins=bins, color=def_colors[name], alpha=0.65, label=name)
ax2.axvline(tau, color='#333333', lw=2, linestyle='--',
label=f'tau = {tau:.3f}')
ax2.set_xlabel('Reconstruction error (k=2)', fontsize=11)
ax2.set_ylabel('Count', fontsize=11)
ax2.set_title('Anomaly score by grain type', fontsize=11)
ax2.legend(fontsize=9)
ax2.grid(alpha=0.2)
fig.suptitle('Rice grain defect detection via PCA reconstruction error', fontsize=12)
fig.tight_layout()
plt.savefig('ch20-pca/fig-rice-defects.png', dpi=150, bbox_inches='tight')
plt.show()