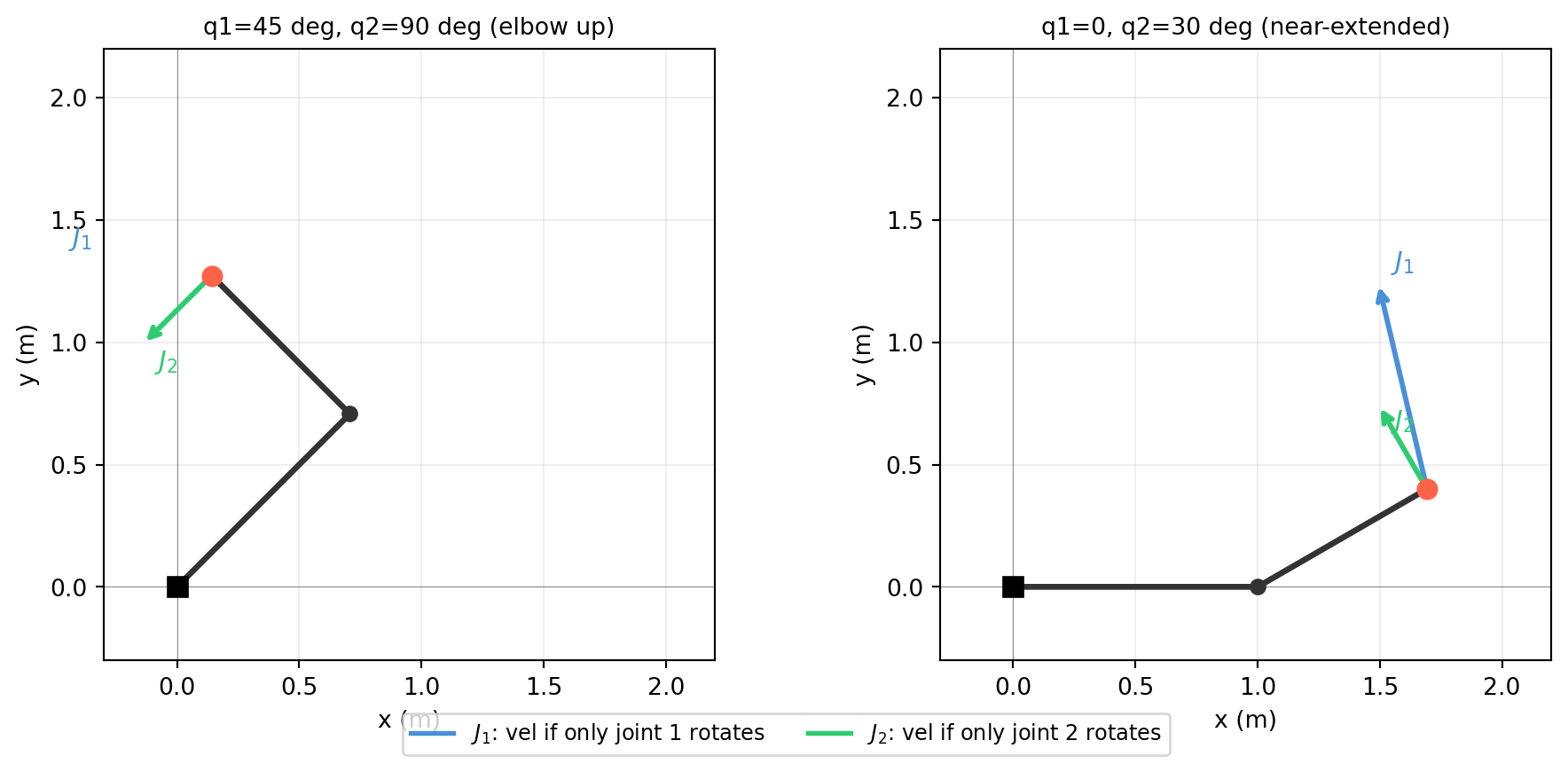
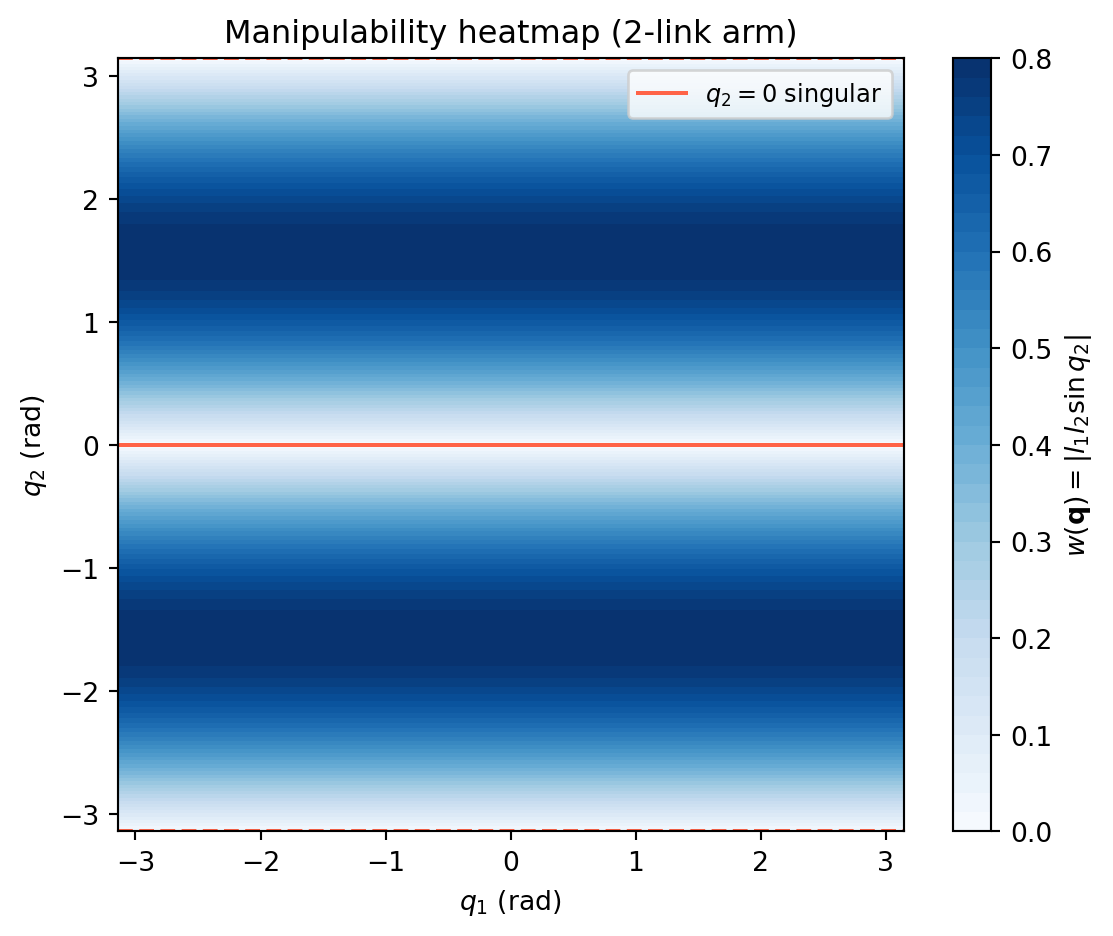
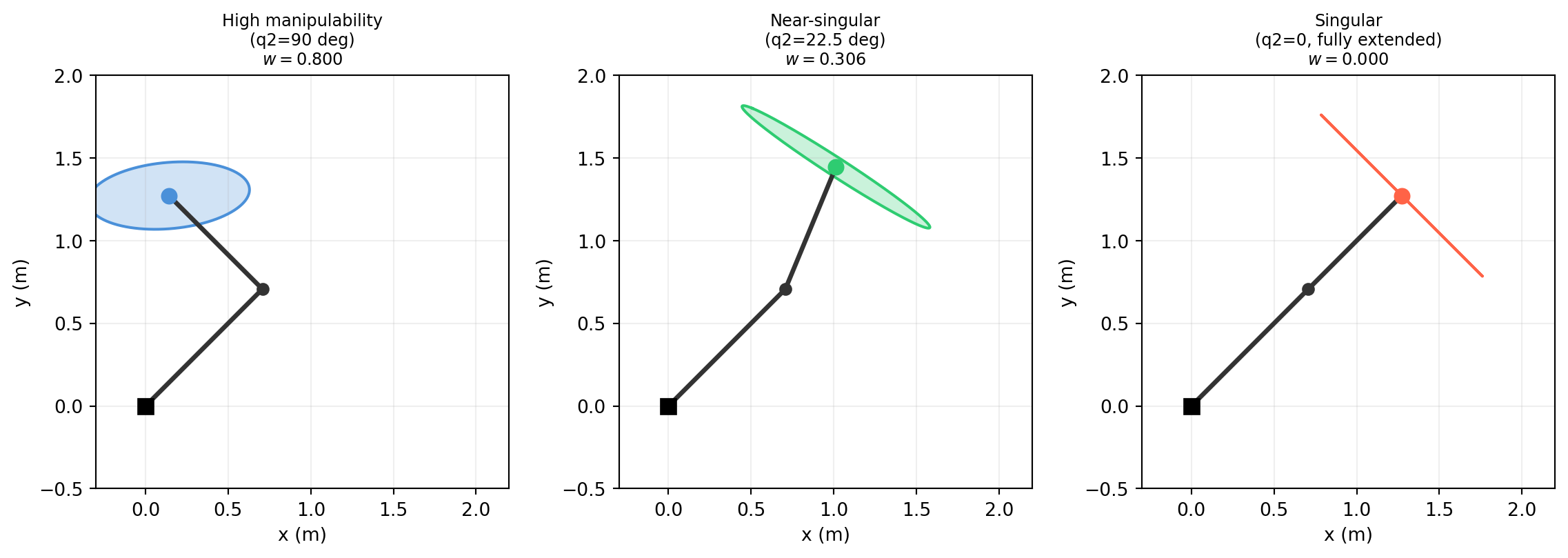
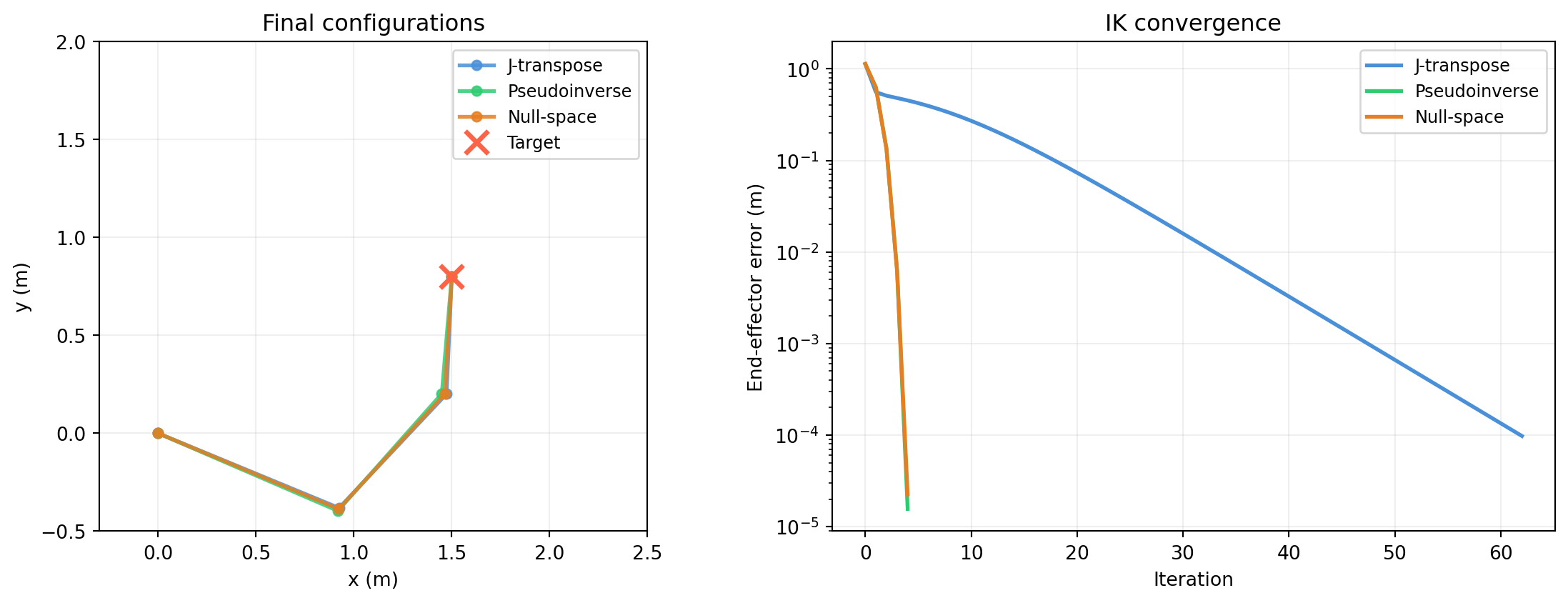
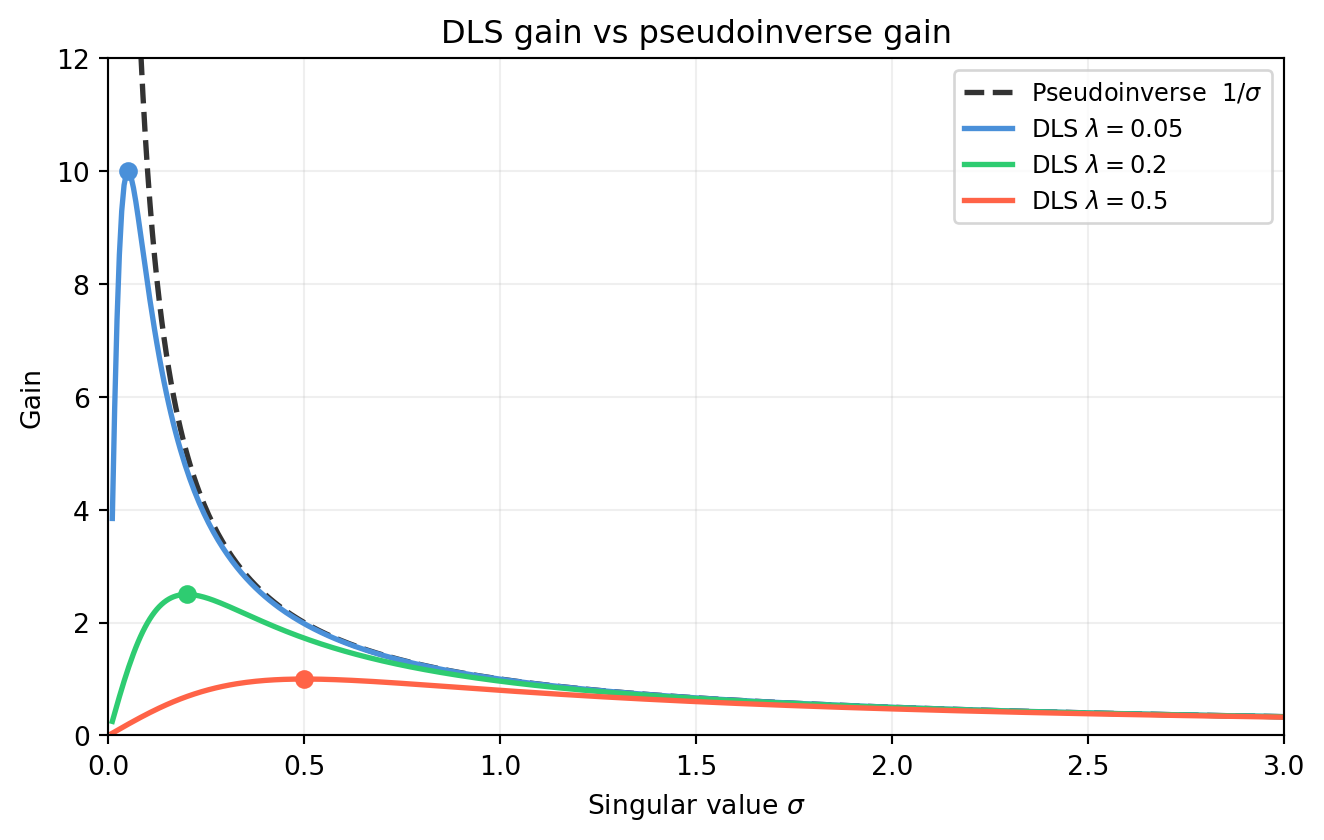
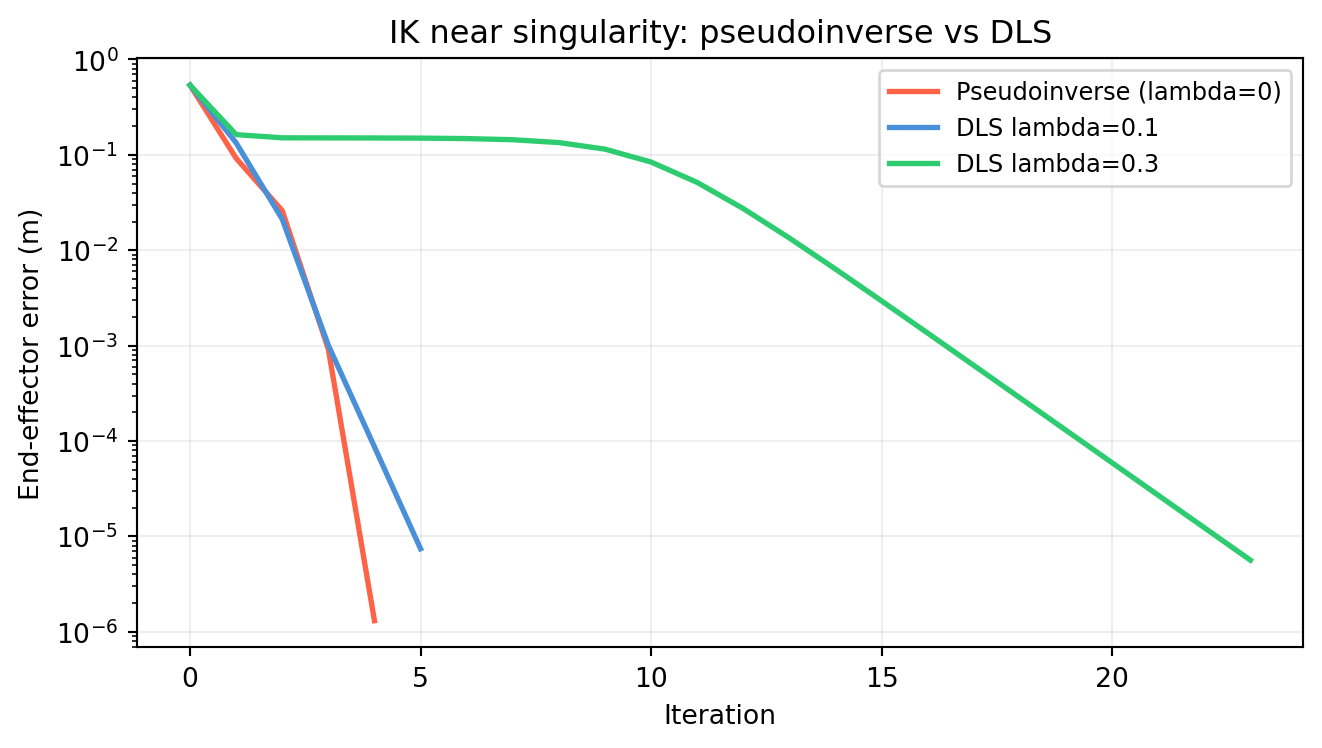
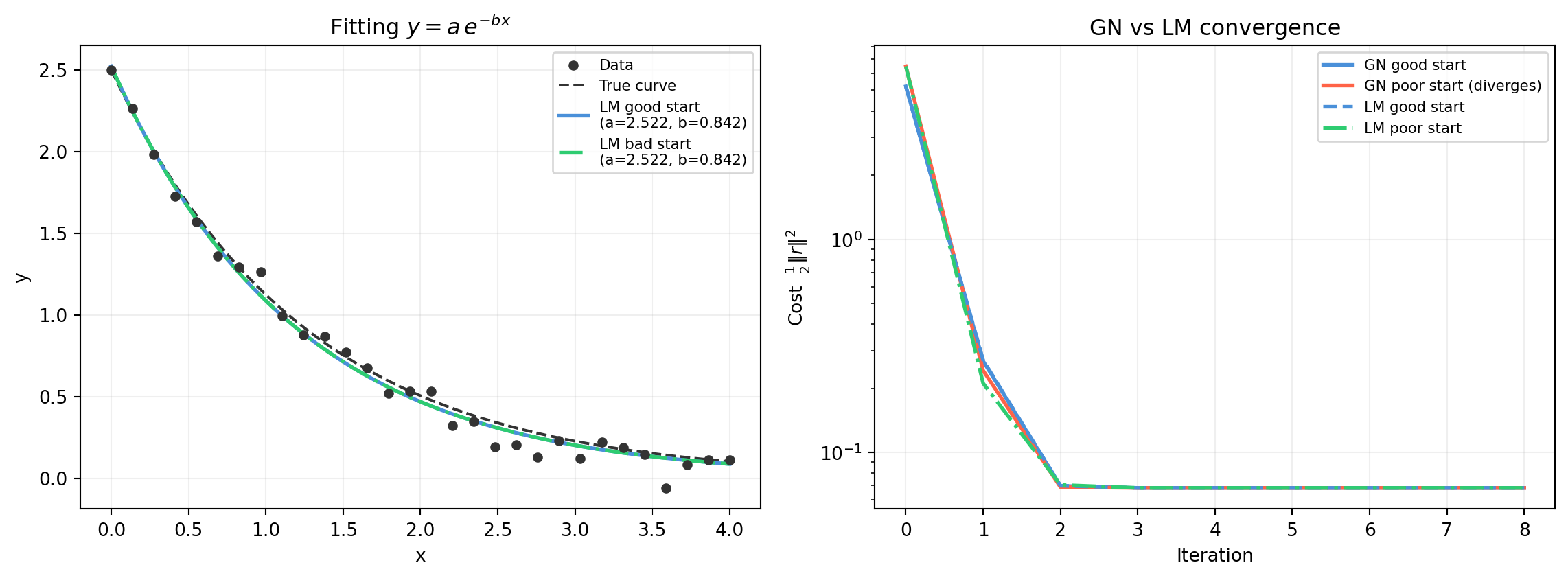
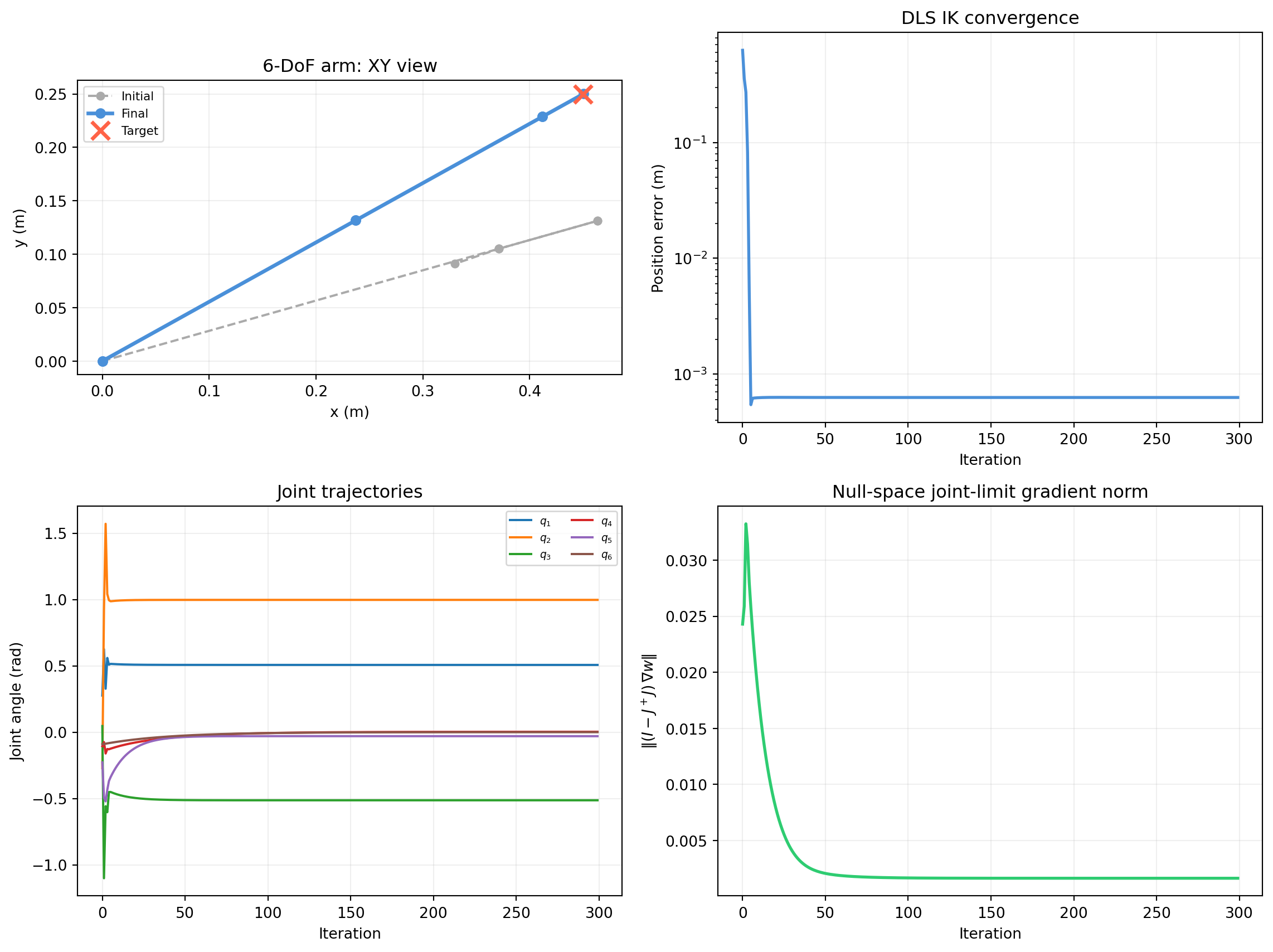
import numpy as np
import matplotlib.pyplot as plt
# DH parameters: theta_offset, d, a, alpha (in radians/meters)
# Simplified Puma-560-like arm at unit scale
DH = np.array([
[0.0, 0.65, 0.0, np.pi/2], # joint 1
[0.0, 0.0, 0.50, 0.0 ], # joint 2
[0.0, 0.0, 0.0, np.pi/2], # joint 3
[0.0, 0.43, 0.0, -np.pi/2], # joint 4
[0.0, 0.0, 0.0, np.pi/2], # joint 5
[0.0, 0.10, 0.0, 0.0 ], # joint 6
]) # shape (6, 4)
# Joint limits [q_min, q_max] in radians
Q_LIM = np.array([
[-np.pi, np.pi ], # joint 1
[-np.pi/2, np.pi/2 ], # joint 2
[-np.pi, np.pi ], # joint 3
[-np.pi, np.pi ], # joint 4
[-np.pi/2, np.pi/2 ], # joint 5
[-np.pi, np.pi ], # joint 6
]) # shape (6, 2)
def dh_matrix(theta, d, a, alpha):
"""Single DH transform T_{i-1}^{i}."""
ct, st = np.cos(theta), np.sin(theta)
ca, sa = np.cos(alpha), np.sin(alpha)
T = np.array([
[ct, -st*ca, st*sa, a*ct],
[st, ct*ca, -ct*sa, a*st],
[0.0, sa, ca, d],
[0.0, 0.0, 0.0, 1.0],
]) # shape (4, 4)
return T
def fk_6dof(q):
"""
Forward kinematics for 6-DoF DH arm.
Returns list of 4x4 transforms: frames[i] = T_{0}^{i} (i=0..6, i=0 is base).
"""
n = len(q)
frames = [np.eye(4)] # shape list of (4, 4)
for i in range(n):
theta = q[i] + DH[i, 0]
d, a, alpha = DH[i, 1], DH[i, 2], DH[i, 3]
T = dh_matrix(theta, d, a, alpha) # shape (4, 4)
frames.append(frames[-1] @ T)
return frames
def geometric_jacobian_pos(q):
"""
3 x 6 position-only geometric Jacobian.
J[:, i] = z_{i-1} x (p_e - p_{i-1}) for revolute joint i.
"""
frames = fk_6dof(q)
pe = frames[-1][:3, 3] # shape (3,)
J = np.zeros((3, 6)) # shape (3, 6)
for i in range(6):
z_prev = frames[i][:3, 2] # shape (3,) -- z-axis of frame i
p_prev = frames[i][:3, 3] # shape (3,)
J[:, i] = np.cross(z_prev, pe - p_prev) # shape (3,)
return J
def joint_limit_gradient(q):
"""
Secondary objective: gradient of -sum_i (q_i - q_mid_i)^2 / range_i^2.
Drives joints toward center of range. Returns shape (6,).
"""
q_mid = 0.5 * (Q_LIM[:, 0] + Q_LIM[:, 1]) # shape (6,)
q_range = Q_LIM[:, 1] - Q_LIM[:, 0] # shape (6,)
g = -2.0 * (q - q_mid) / (q_range**2) # shape (6,)
return g
def dls_ik_6dof(q0, p_target, lam=0.05, beta=0.3, n_steps=200, tol=1e-4):
"""
DLS IK with null-space joint-limit centering.
Returns final q, position error history, joint angle history, null-space grad norm history.
"""
q = q0.copy() # shape (6,)
errs, q_hist, ns_norms = [], [], []
for _ in range(n_steps):
frames = fk_6dof(q)
pe = frames[-1][:3, 3] # shape (3,)
e = p_target - pe # shape (3,)
err = float(np.linalg.norm(e))
errs.append(err)
q_hist.append(q.copy())
if err < tol:
break
J = geometric_jacobian_pos(q) # shape (3, 6)
A = J @ J.T + lam**2 * np.eye(3) # shape (3, 3)
Jp_e = J.T @ np.linalg.solve(A, e) # shape (6,) DLS step
N = np.eye(6) - J.T @ np.linalg.solve(A, J) # shape (6, 6)
dq0 = beta * joint_limit_gradient(q) # shape (6,)
ns_norms.append(float(np.linalg.norm(N @ dq0)))
dq = Jp_e + N @ dq0 # shape (6,)
q = np.clip(q + dq, Q_LIM[:, 0], Q_LIM[:, 1])
return q, np.array(errs), np.array(q_hist), np.array(ns_norms)
rng = np.random.default_rng(17)
q0 = rng.uniform(-0.4, 0.4, 6) # shape (6,) random start
# Target: slightly inside the arm's workspace
p_target = np.array([0.45, 0.25, 0.60]) # shape (3,)
q_final, errs, q_hist, ns_norms = dls_ik_6dof(
q0, p_target, lam=0.05, beta=0.5, n_steps=300)
frames_init = fk_6dof(q0)
frames_final = fk_6dof(q_final)
# Collect joint origins for plotting (3D projections onto xy and xz)
def arm_pts(frames):
pts = np.array([f[:3, 3] for f in frames]) # shape (7, 3)
return pts
pts_init = arm_pts(frames_init)
pts_final = arm_pts(frames_final)
fig, axes = plt.subplots(2, 2, figsize=(12, 9))
# Top-left: arm in 3D projected to xy
ax = axes[0, 0]
ax.plot(pts_init[:, 0], pts_init[:, 1],
'o--', color='#aaaaaa', lw=1.5, ms=5, label='Initial')
ax.plot(pts_final[:, 0], pts_final[:, 1],
'o-', color='#4a90d9', lw=2.5, ms=6, label='Final')
ax.plot(*p_target[:2], 'x', color='tomato', ms=12, mew=2.5, zorder=5, label='Target')
ax.set_xlabel('x (m)')
ax.set_ylabel('y (m)')
ax.set_title('6-DoF arm: XY view')
ax.set_aspect('equal')
ax.legend(fontsize=8)
ax.grid(alpha=0.2)
# Top-right: IK convergence
ax = axes[0, 1]
ax.semilogy(errs, color='#4a90d9', lw=2)
ax.set_xlabel('Iteration')
ax.set_ylabel('Position error (m)')
ax.set_title('DLS IK convergence')
ax.grid(alpha=0.2)
# Bottom-left: joint angles over iterations
ax = axes[1, 0]
for i in range(6):
ax.plot(q_hist[:, i], lw=1.5, label=f'$q_{i+1}$')
ax.set_xlabel('Iteration')
ax.set_ylabel('Joint angle (rad)')
ax.set_title('Joint trajectories')
ax.legend(fontsize=7, ncol=2)
ax.grid(alpha=0.2)
# Bottom-right: null-space gradient norm
ax = axes[1, 1]
ax.plot(ns_norms, color='#2ecc71', lw=2)
ax.set_xlabel('Iteration')
ax.set_ylabel(r'$\|(I - J^+J)\,\nabla w\|$')
ax.set_title('Null-space joint-limit gradient norm')
ax.grid(alpha=0.2)
plt.tight_layout()
plt.show()
# Report final position error
frames_check = fk_6dof(q_final)
pe_final = frames_check[-1][:3, 3] # shape (3,)
err_final = float(np.linalg.norm(pe_final - p_target))
print(f"Final position error: {err_final:.6f} m")
print(f"Target: [{p_target[0]:.4f}, {p_target[1]:.4f}, {p_target[2]:.4f}]")
print(f"Achieved: [{pe_final[0]:.4f}, {pe_final[1]:.4f}, {pe_final[2]:.4f}]")