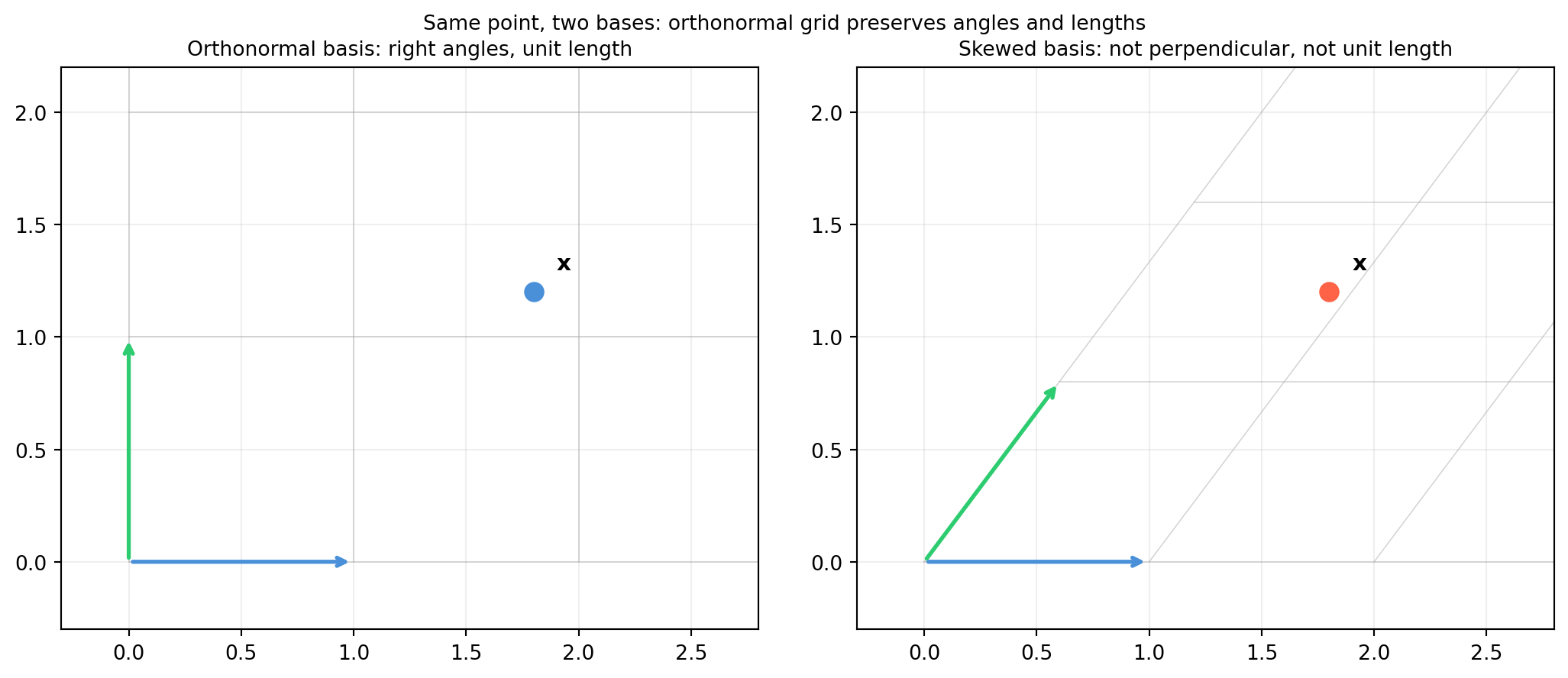
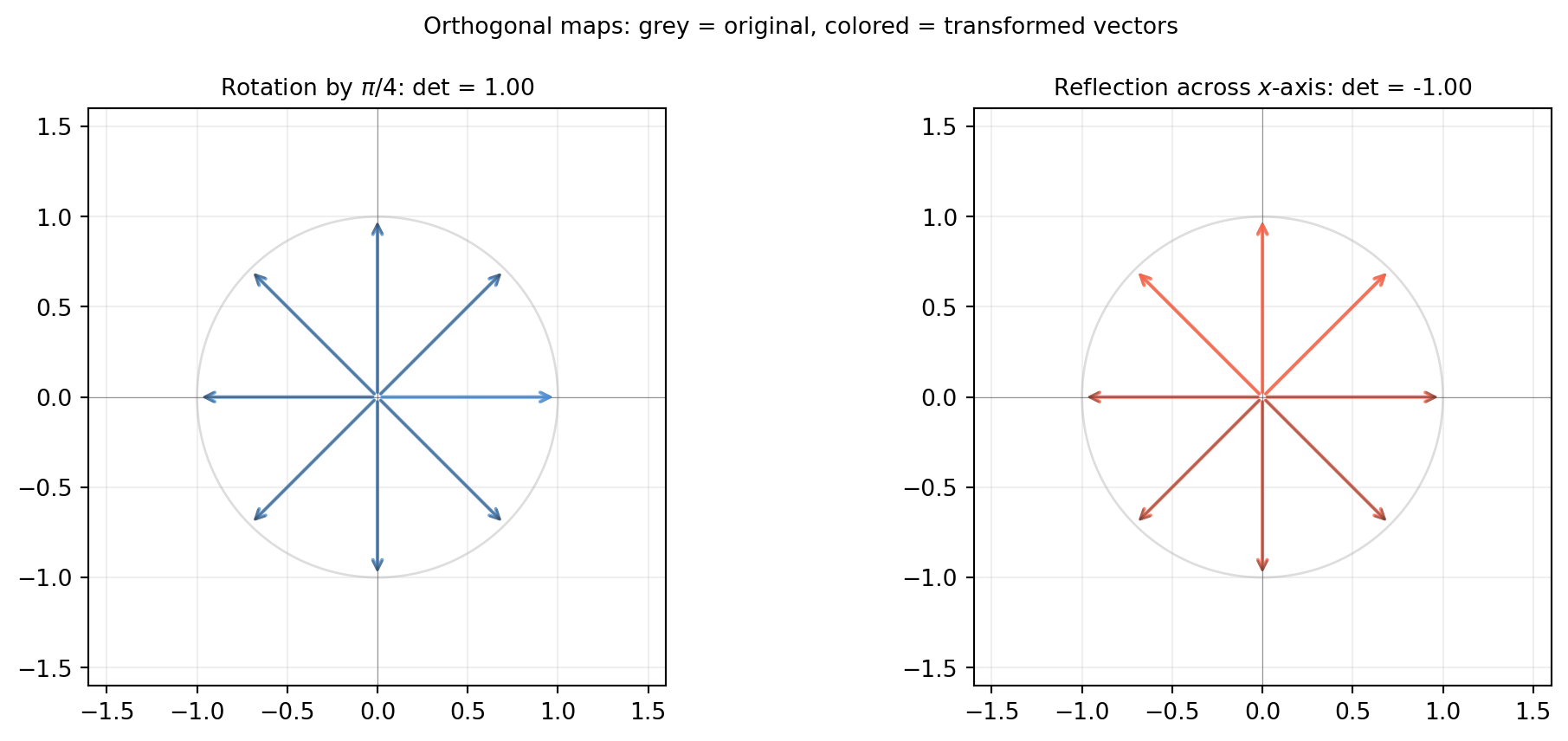
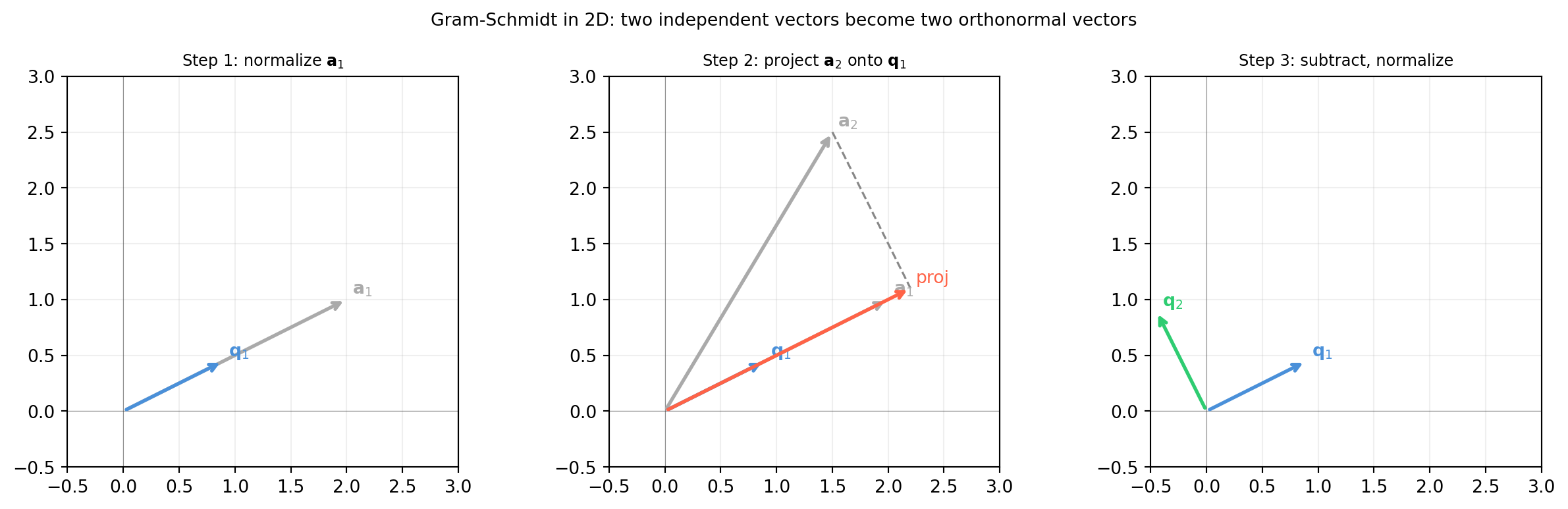
import numpy as np
import matplotlib.pyplot as plt
a1 = np.array([2.0, 1.0]) # shape (2,)
a2 = np.array([1.5, 2.5]) # shape (2,)
# Step 1
q1 = a1 / np.linalg.norm(a1) # shape (2,)
# Step 2
proj = float(q1 @ a2) * q1 # shape (2,) -- projection of a2 onto q1
v2 = a2 - proj # shape (2,) -- residual
q2 = v2 / np.linalg.norm(v2) # shape (2,)
fig, axes = plt.subplots(1, 3, figsize=(13, 4))
data = [
('Step 1: normalize $\\mathbf{a}_1$',
[(a1, '#aaaaaa', r'$\mathbf{a}_1$'),
(q1, '#4a90d9', r'$\mathbf{q}_1$')], []),
('Step 2: project $\\mathbf{a}_2$ onto $\\mathbf{q}_1$',
[(a1, '#aaaaaa', r'$\mathbf{a}_1$'),
(a2, '#aaaaaa', r'$\mathbf{a}_2$'),
(q1, '#4a90d9', r'$\mathbf{q}_1$'),
(proj, 'tomato', r'proj')],
[(a2, proj, '--', '#888888')]),
('Step 3: subtract, normalize',
[(q1, '#4a90d9', r'$\mathbf{q}_1$'),
(q2, '#2ecc71', r'$\mathbf{q}_2$')], []),
]
for ax, (title, vecs, lines) in zip(axes, data):
ax.set_xlim(-0.5, 3.0)
ax.set_ylim(-0.5, 3.0)
ax.set_aspect('equal')
ax.axhline(0, color='#333333', lw=0.4, alpha=0.5)
ax.axvline(0, color='#333333', lw=0.4, alpha=0.5)
ax.grid(True, alpha=0.2)
ax.set_title(title, fontsize=9)
for v, c, lbl in vecs:
ax.annotate('', xy=(v[0], v[1]), xytext=[0, 0],
arrowprops=dict(arrowstyle='->', color=c, lw=2))
ax.text(v[0] + 0.05, v[1] + 0.05, lbl, fontsize=10, color=c)
for start, end, ls, c in lines:
ax.plot([start[0], end[0]], [start[1], end[1]], ls=ls, color=c, lw=1.2)
plt.suptitle('Gram-Schmidt in 2D: two independent vectors become two orthonormal vectors',
fontsize=10)
plt.tight_layout()
plt.show()
print(f"q1 . q2 = {float(q1 @ q2):.2e} (orthogonal)")
print(f"||q1|| = {np.linalg.norm(q1):.6f}, ||q2|| = {np.linalg.norm(q2):.6f} (unit)")