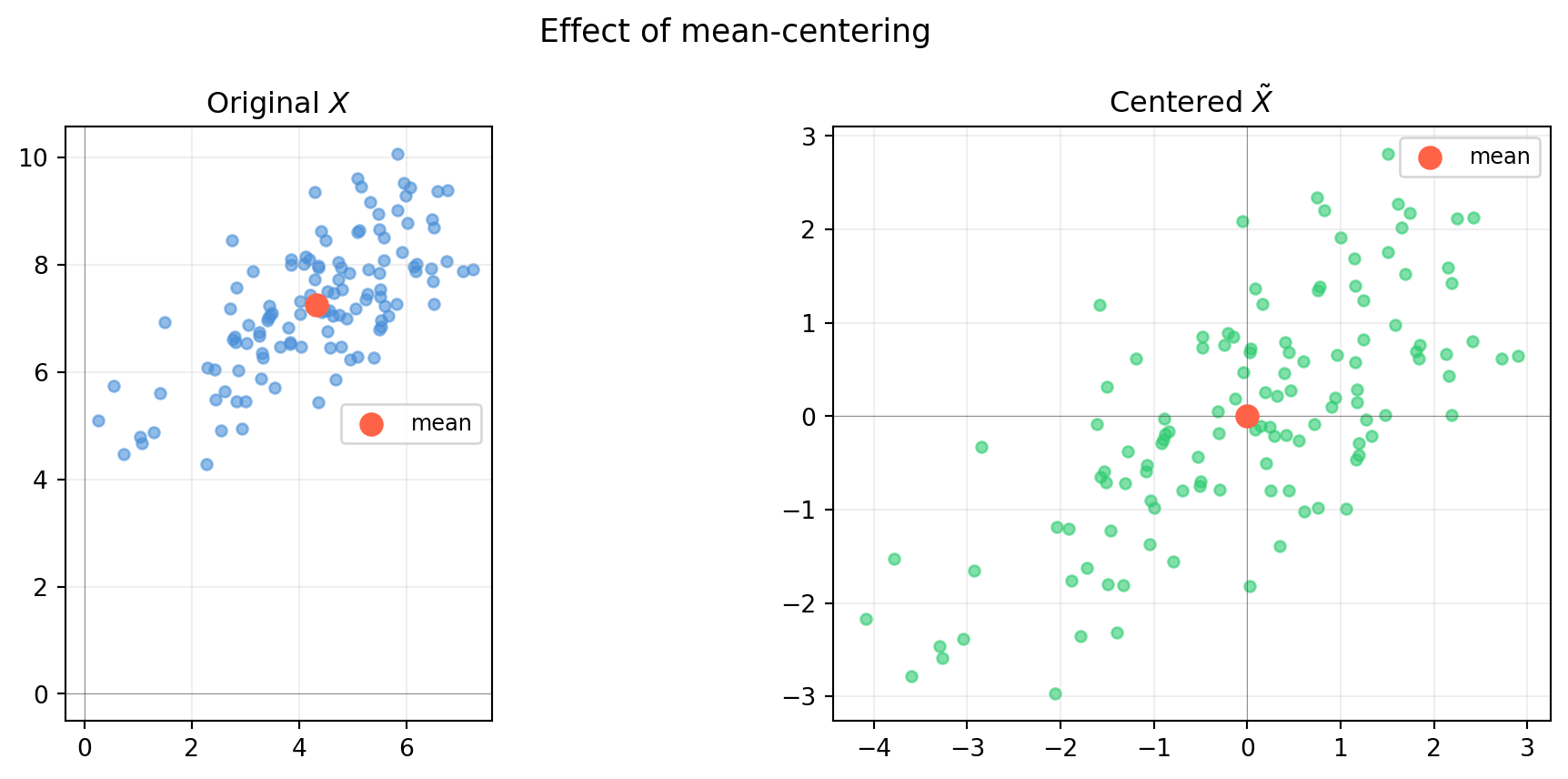
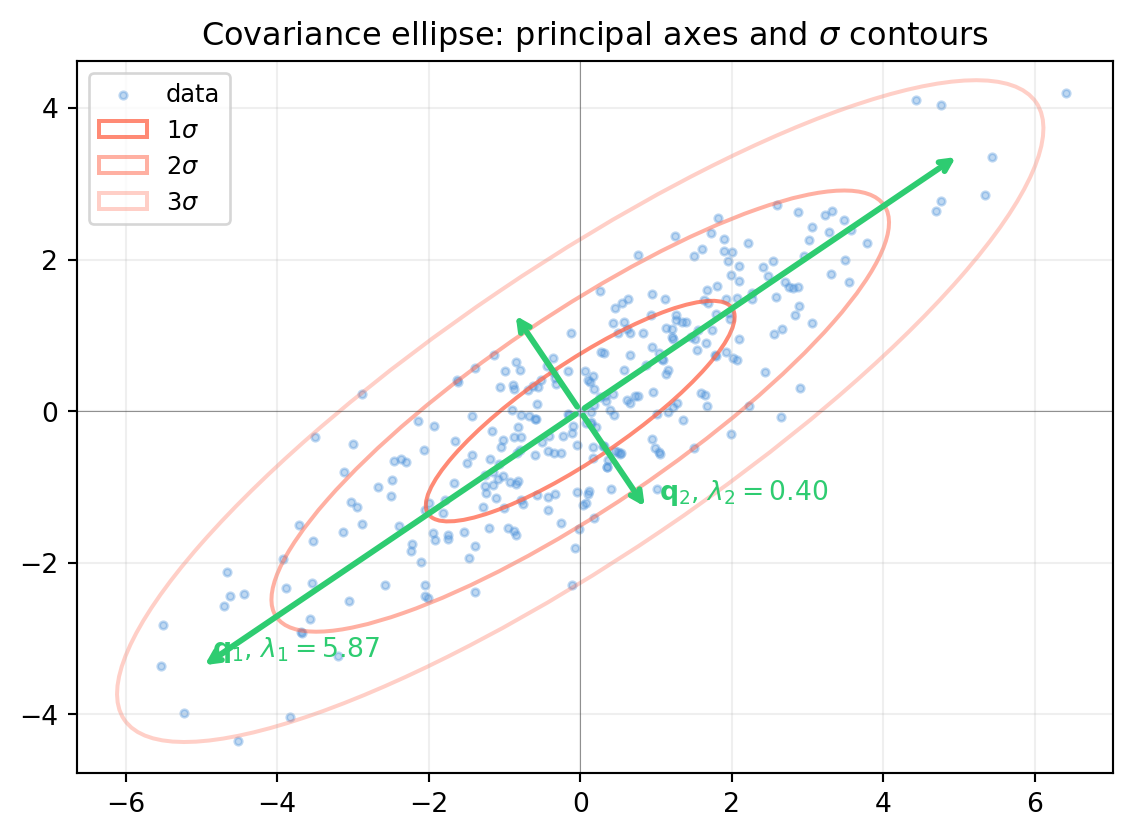
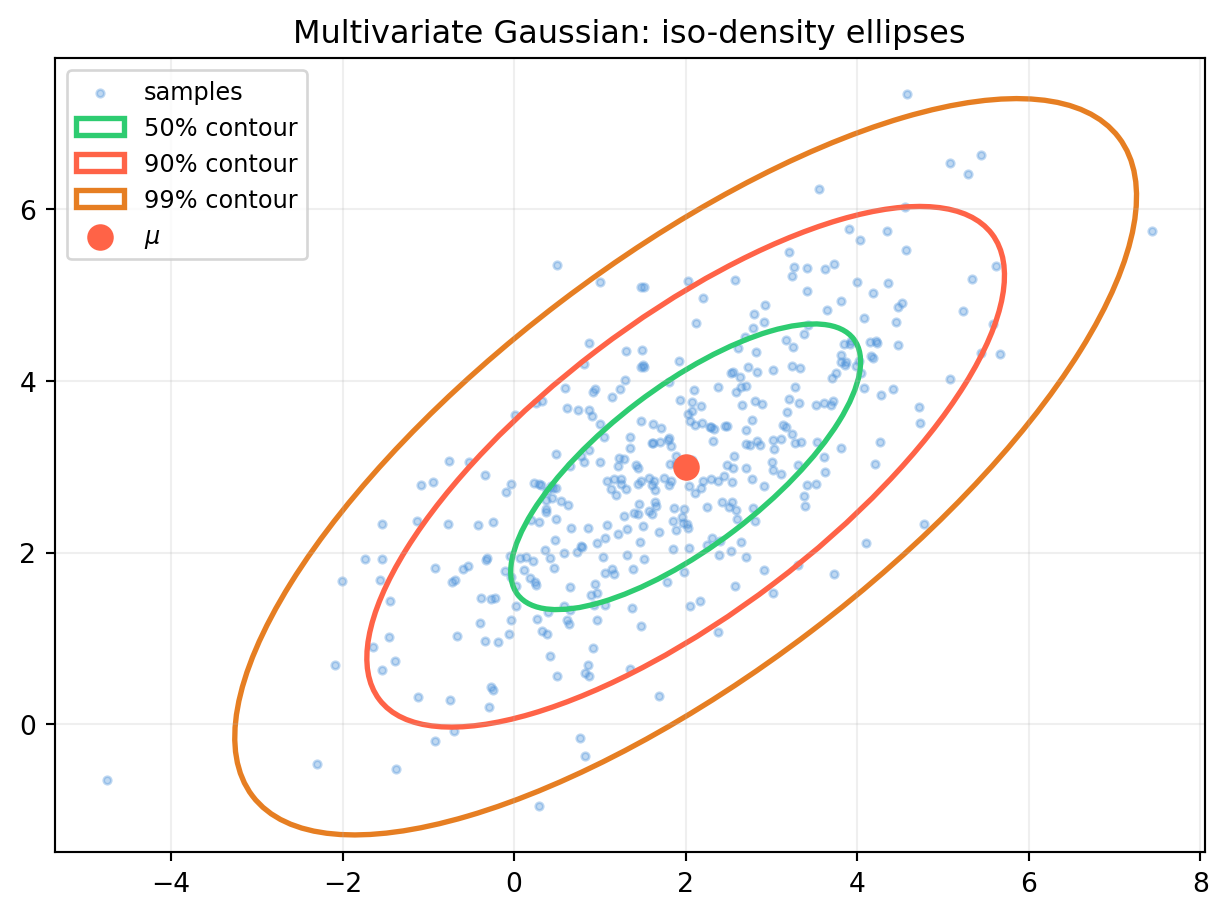
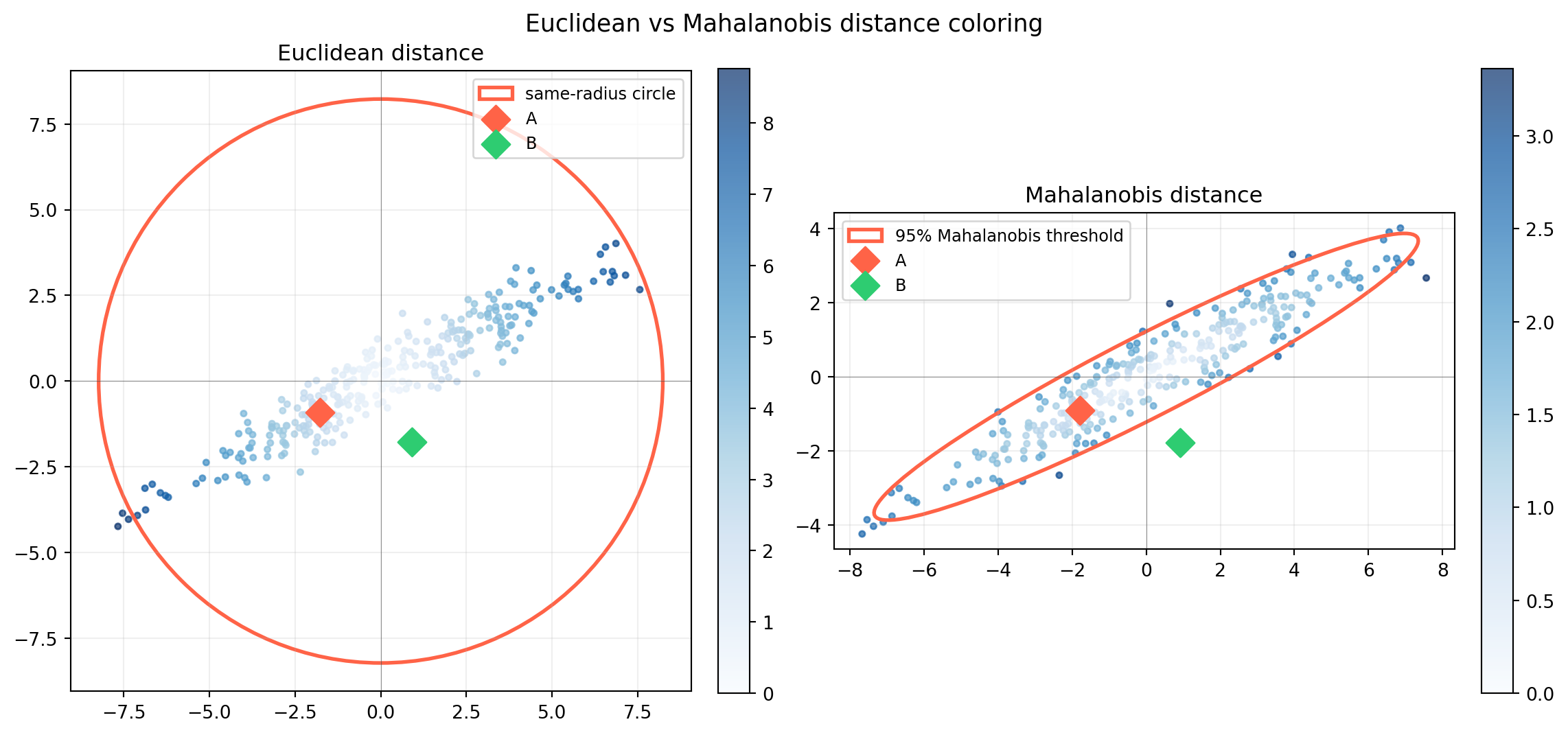
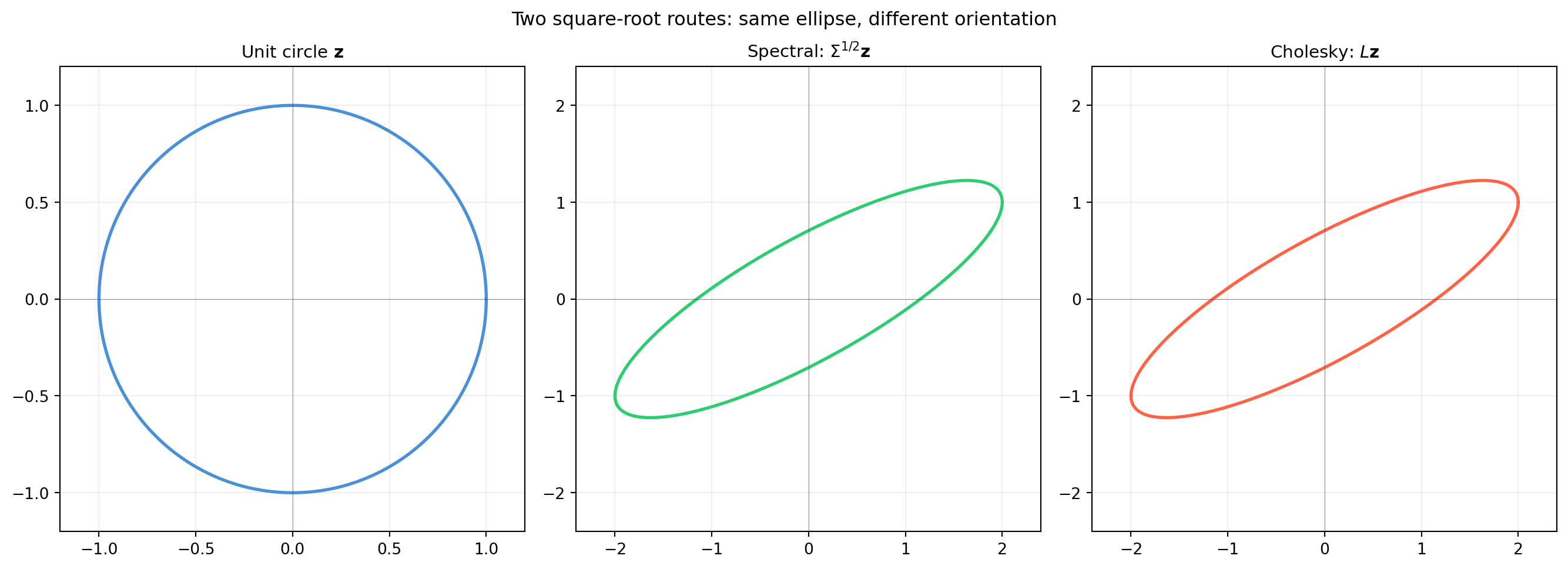
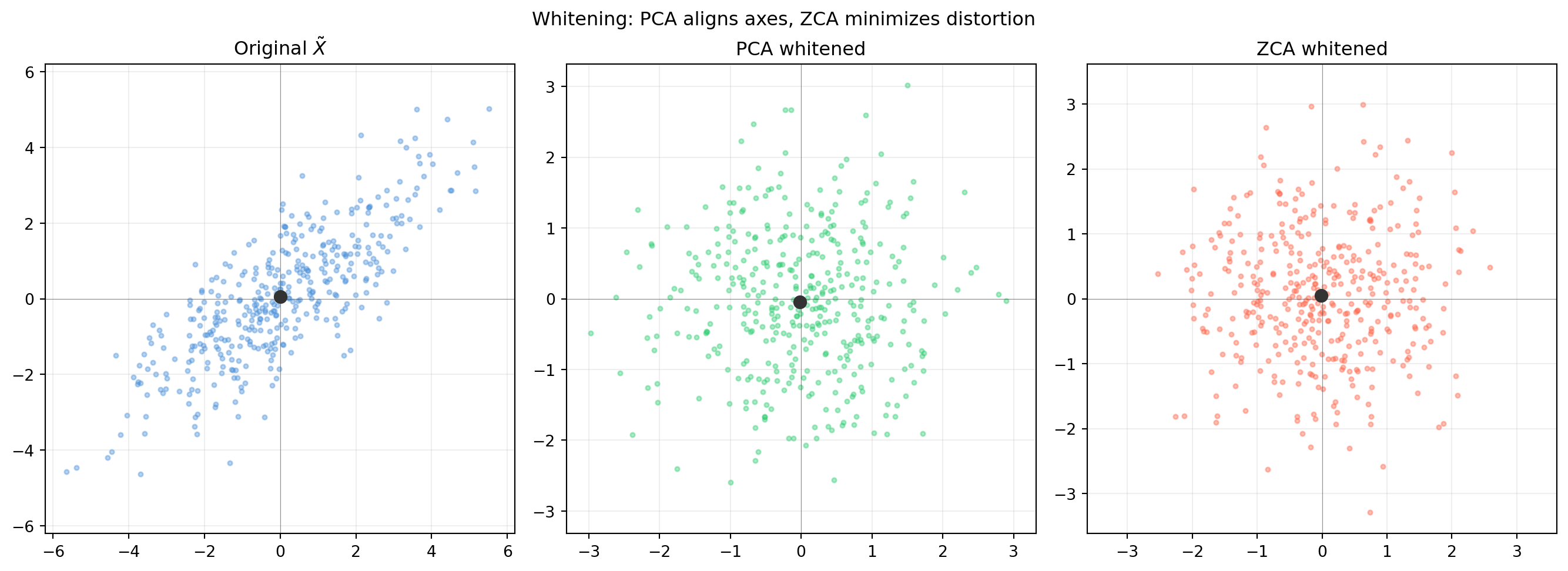
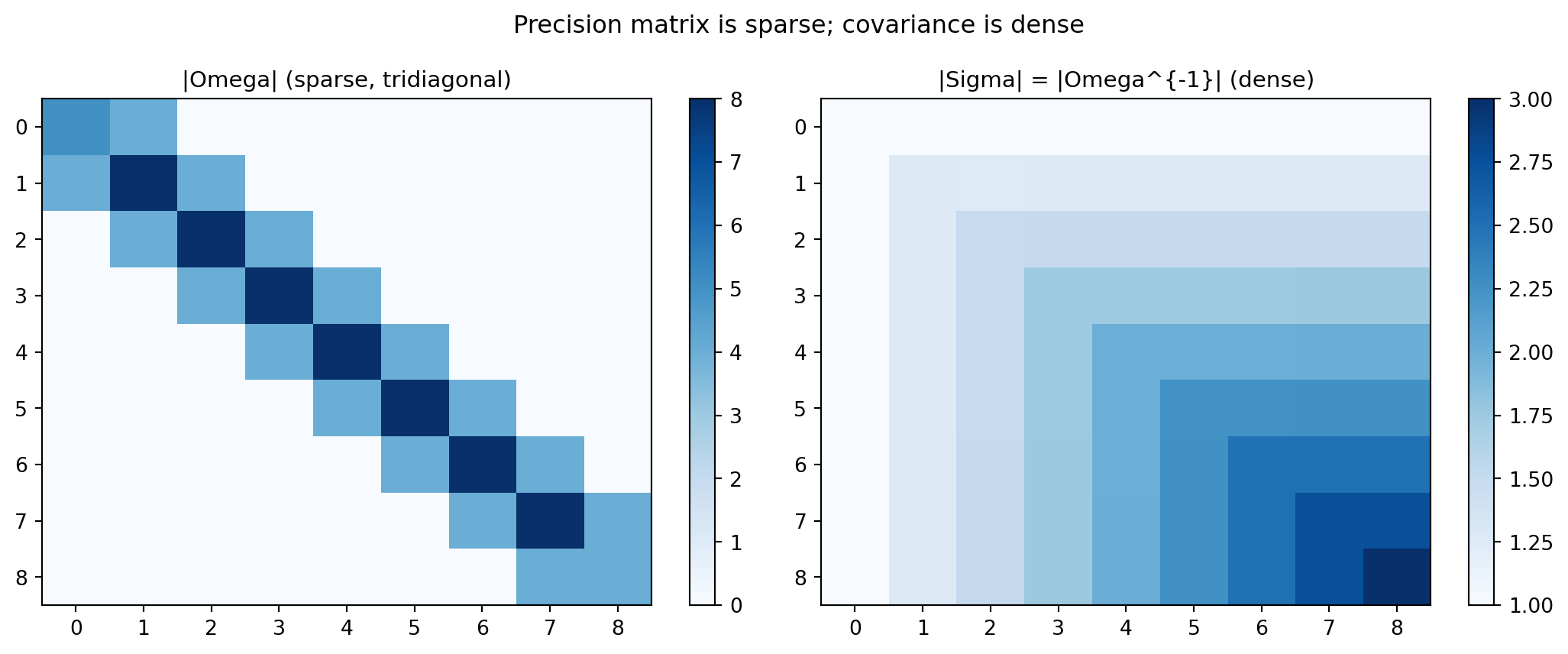
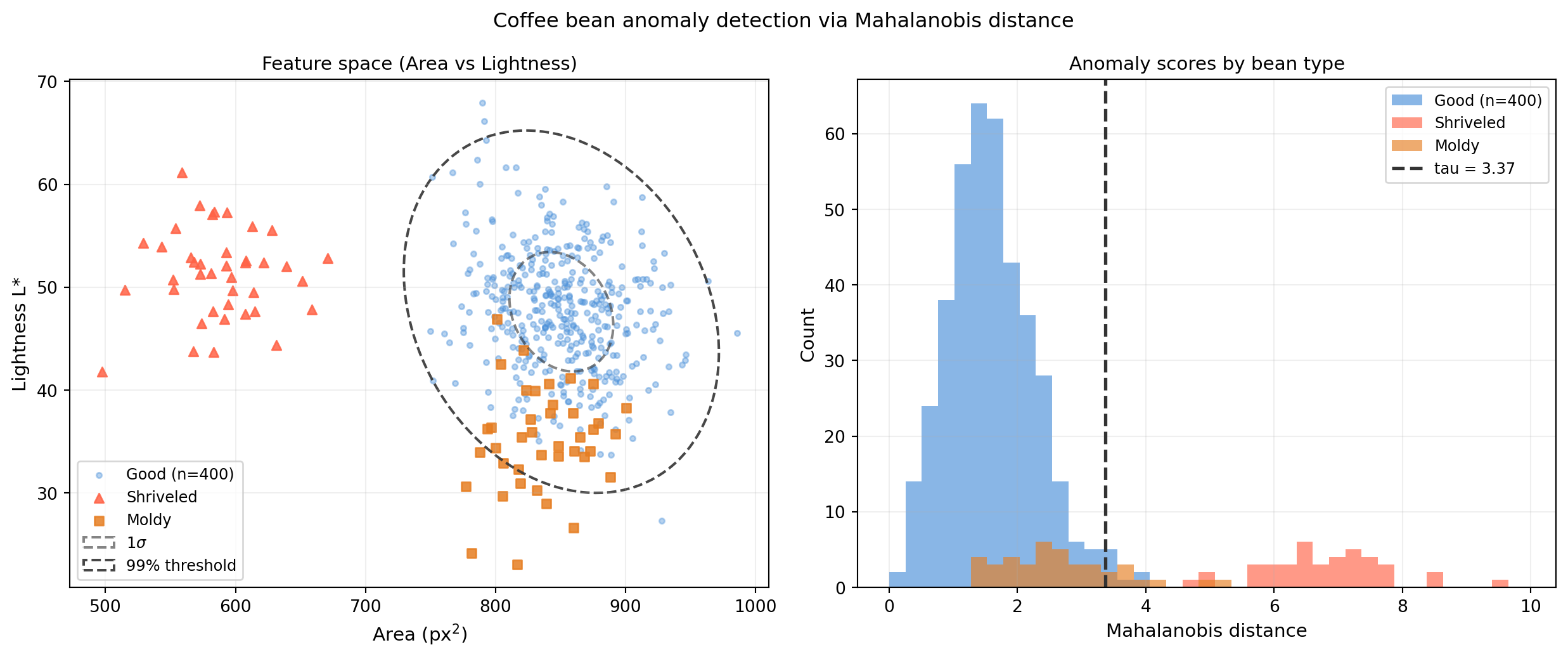
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Ellipse
from scipy.stats import chi2
rng = np.random.default_rng(1982)
# Re-generate (self-contained)
mu_good = np.array([850.0, 0.72, 48.0])
Sigma_true = np.array([[1600.0, 0.8, -48.0],
[ 0.8, 0.006, 0.07],
[ -48.0, 0.07, 36.0]])
L_true = np.linalg.cholesky(Sigma_true)
n_good = 400
X_good = rng.standard_normal((n_good, 3)) @ L_true.T + mu_good
mu_shriv = np.array([580.0, 0.52, 51.0])
X_shriv = rng.standard_normal((40, 3)) @ np.linalg.cholesky(
np.diag([900.0, 0.008, 25.0])).T + mu_shriv
mu_mold = np.array([830.0, 0.70, 35.0])
X_mold = rng.standard_normal((40, 3)) @ np.linalg.cholesky(
np.diag([1200.0, 0.005, 20.0])).T + mu_mold
mu_hat = X_good.mean(axis=0)
X_c = X_good - mu_hat
Sigma_hat = X_c.T @ X_c / (n_good - 1)
L_hat = np.linalg.cholesky(Sigma_hat)
def mahalanobis(X, mu, L):
diff = X - mu
Z = np.linalg.solve(L, diff.T).T
return np.linalg.norm(Z, axis=1)
tau = np.sqrt(chi2.ppf(0.99, df=3))
d_good = mahalanobis(X_good, mu_hat, L_hat)
d_shriv = mahalanobis(X_shriv, mu_hat, L_hat)
d_mold = mahalanobis(X_mold, mu_hat, L_hat)
# Project to 2-D subspace: Area (feat 0) vs Lightness (feat 2) for visualization
feat_x, feat_y = 0, 2
labels_x = ['Area (px$^2$)', 'Eccentricity', 'Lightness L*']
# Marginal covariance for the 2-D projection
idx2 = [feat_x, feat_y]
Sigma_2d = Sigma_hat[np.ix_(idx2, idx2)] # shape (2, 2)
mu_2d = mu_hat[idx2] # shape (2,)
lam2, Q2 = np.linalg.eigh(Sigma_2d)
ord2 = np.argsort(lam2)[::-1]
lam2 = lam2[ord2]; Q2 = Q2[:, ord2]
angle2 = np.degrees(np.arctan2(Q2[1, 0], Q2[0, 0]))
fig, axes = plt.subplots(1, 2, figsize=(13, 5.5))
# Left: scatter in 2-D feature space
ax = axes[0]
ax.scatter(X_good[:, feat_x], X_good[:, feat_y],
s=10, color='#4a90d9', alpha=0.4, label=f'Good (n={n_good})')
ax.scatter(X_shriv[:, feat_x], X_shriv[:, feat_y],
s=30, color='tomato', alpha=0.85, marker='^', label='Shriveled')
ax.scatter(X_mold[:, feat_x], X_mold[:, feat_y],
s=30, color='#e67e22', alpha=0.85, marker='s', label='Moldy')
# 99% Mahalanobis ellipse (marginal 2-D; chi2 df=2 for 2-D projection)
tau_2d = np.sqrt(chi2.ppf(0.99, df=2))
for n_sig, alpha_ell in [(1, 0.6), (tau_2d, 0.9)]:
lbl = '99% threshold' if n_sig == tau_2d else '1$\\sigma$'
ell = Ellipse(xy=mu_2d,
width = 2 * n_sig * np.sqrt(lam2[0]),
height = 2 * n_sig * np.sqrt(lam2[1]),
angle=angle2, edgecolor='#333333', facecolor='none',
lw=1.5, linestyle='--', alpha=alpha_ell, label=lbl)
ax.add_patch(ell)
ax.set_xlabel(labels_x[feat_x], fontsize=11)
ax.set_ylabel(labels_x[feat_y], fontsize=11)
ax.set_title('Feature space (Area vs Lightness)', fontsize=11)
ax.legend(fontsize=9)
ax.grid(alpha=0.2)
# Right: Mahalanobis distance histogram
ax2 = axes[1]
all_d = np.concatenate([d_good, d_shriv, d_mold])
bins = np.linspace(0, all_d.max() * 1.05, 40)
ax2.hist(d_good, bins=bins, color='#4a90d9', alpha=0.65, label=f'Good (n={n_good})')
ax2.hist(d_shriv, bins=bins, color='tomato', alpha=0.65, label='Shriveled')
ax2.hist(d_mold, bins=bins, color='#e67e22', alpha=0.65, label='Moldy')
ax2.axvline(tau, color='#333333', lw=2, linestyle='--', label=f'tau = {tau:.2f}')
ax2.set_xlabel('Mahalanobis distance', fontsize=11)
ax2.set_ylabel('Count', fontsize=11)
ax2.set_title('Anomaly scores by bean type', fontsize=11)
ax2.legend(fontsize=9)
ax2.grid(alpha=0.2)
fig.suptitle('Coffee bean anomaly detection via Mahalanobis distance', fontsize=12)
fig.tight_layout()
plt.savefig('ch19-covariance/fig-coffee-anomaly.png', dpi=150, bbox_inches='tight')
plt.show()