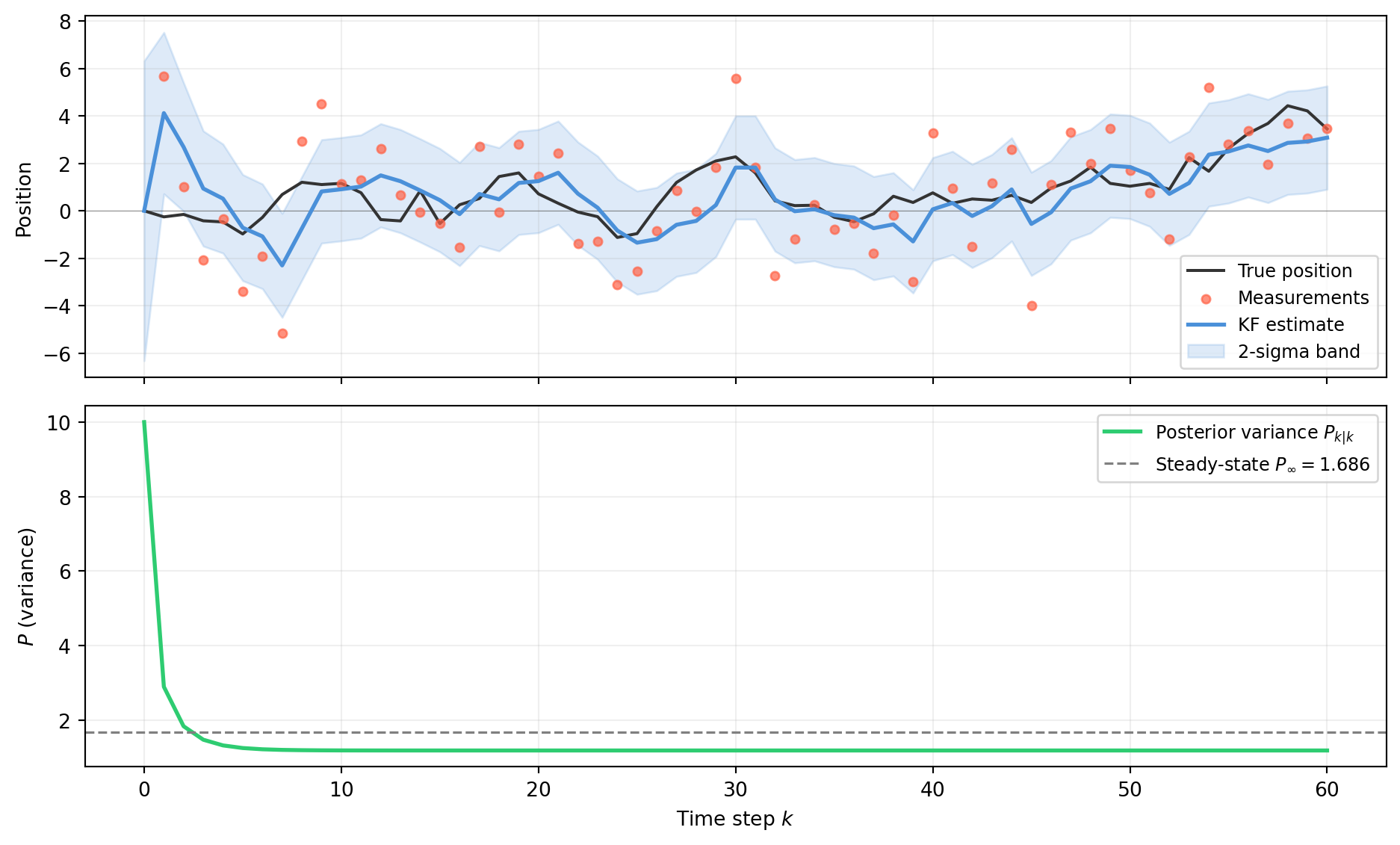
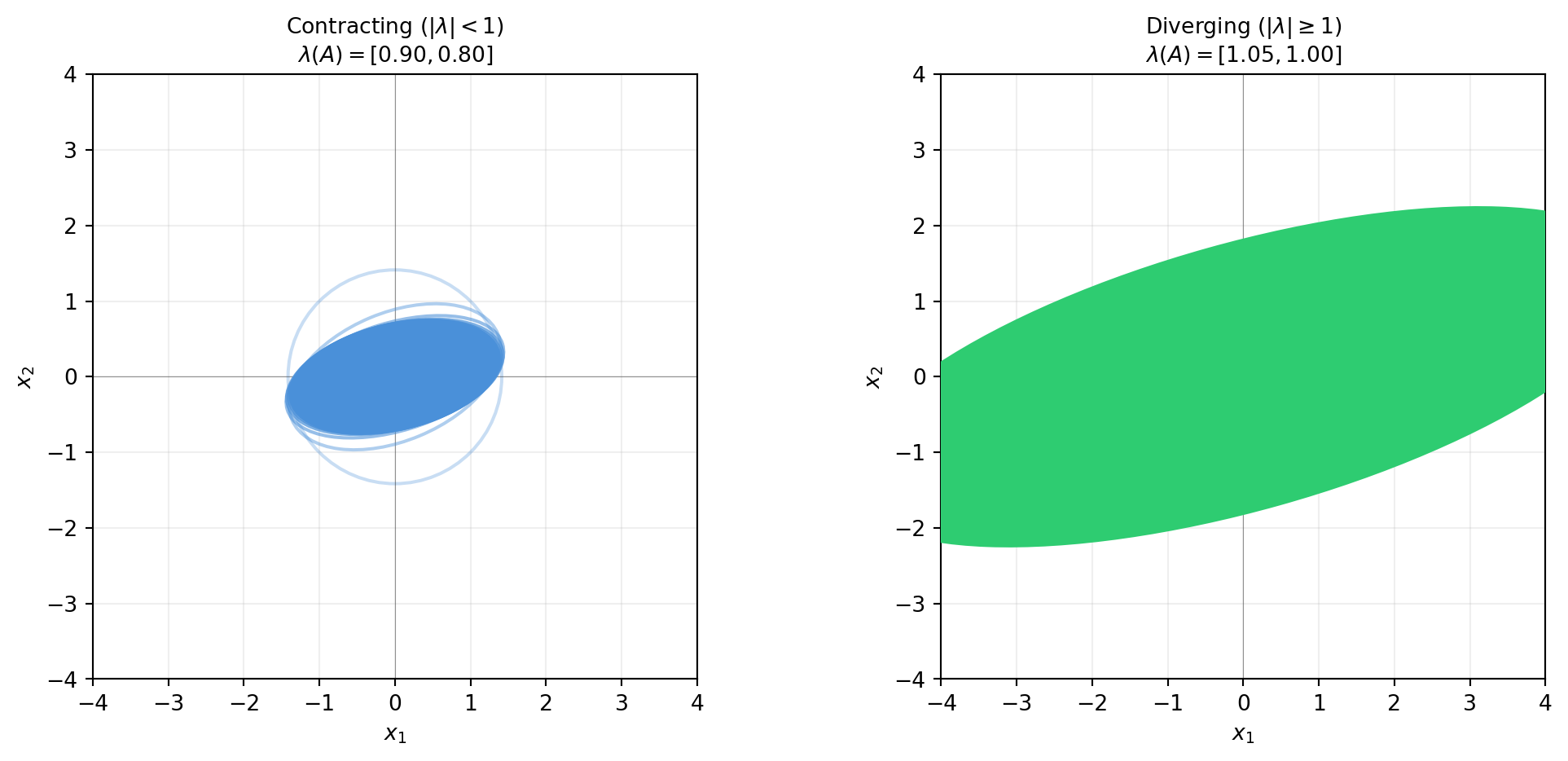
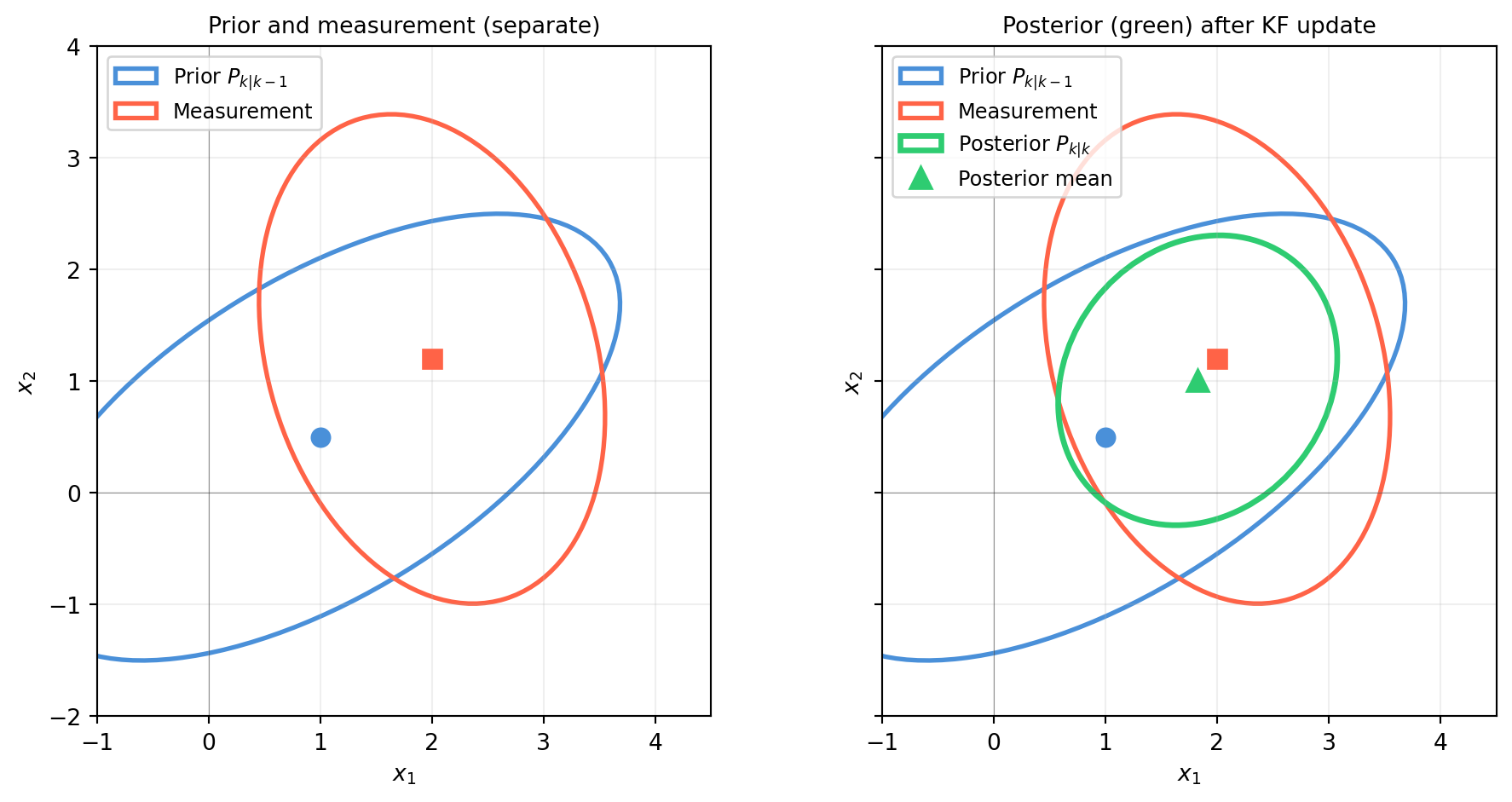
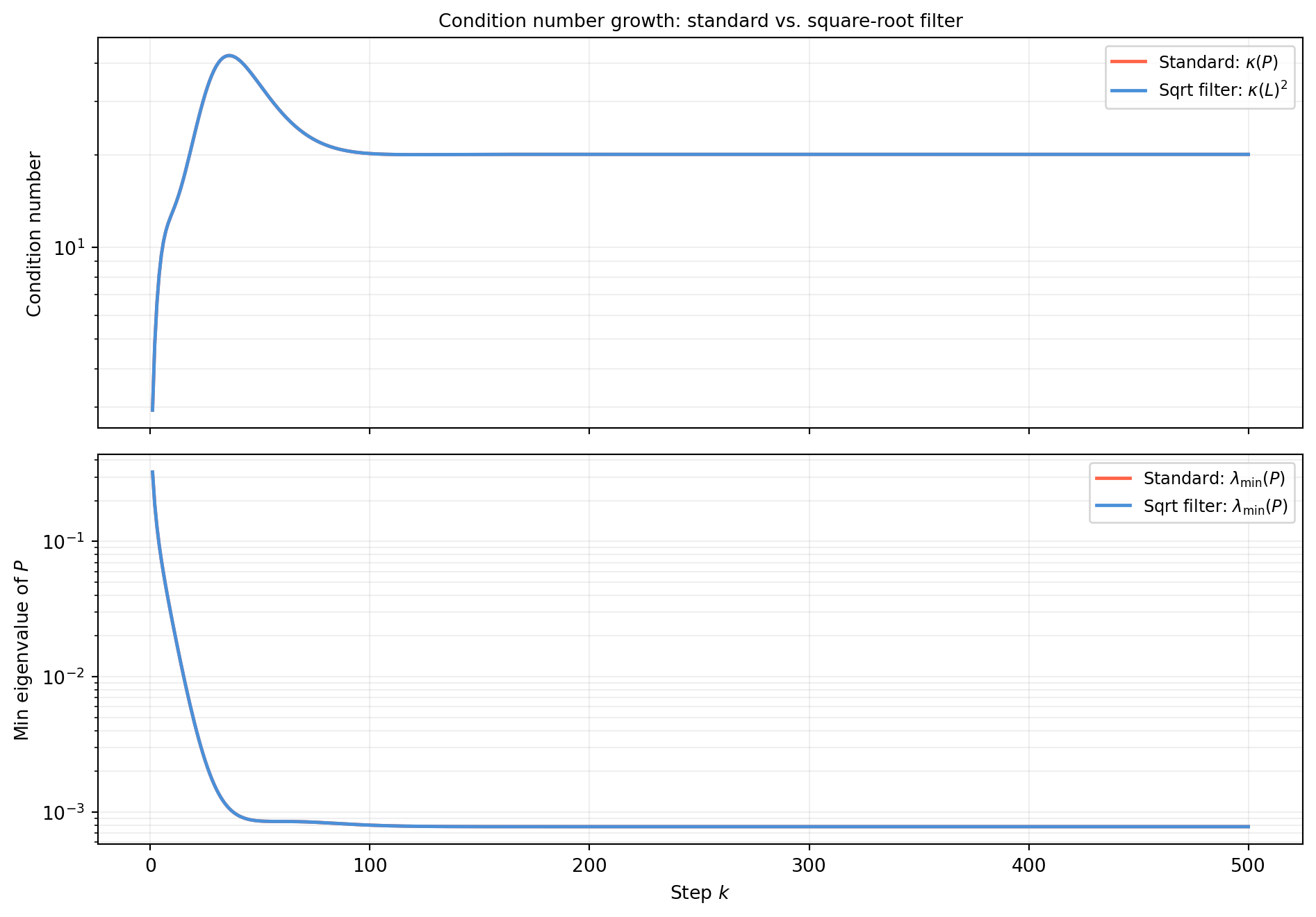
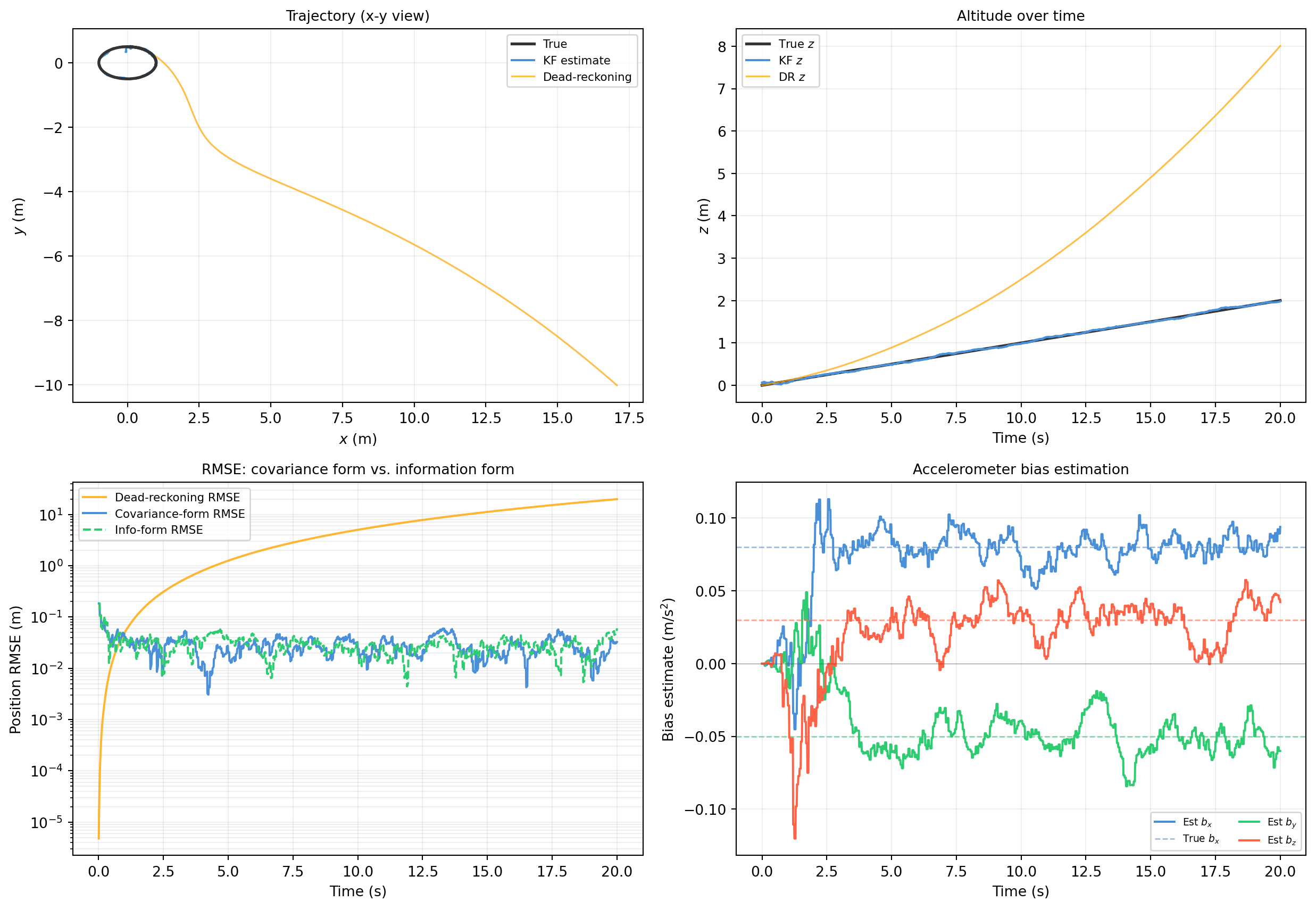
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(237)
# ---- timing parameters ----
dt_imu = 0.01 # IMU at 100 Hz
dt_cam = 0.05 # camera at 20 Hz (every 5 IMU steps)
T_total = 20.0 # seconds
n_imu = int(T_total / dt_imu) # 2000 IMU steps
cam_period = int(dt_cam / dt_imu) # 5 IMU steps between camera measurements
# ---- noise parameters ----
sigma_a = 0.05 # IMU accelerometer noise (m/s^2 per step sqrt)
sigma_b = 0.002 # bias random walk noise
sigma_cam = 0.05 # camera position noise (m)
R_a = (sigma_a**2) * np.eye(3) # shape (3, 3)
Q_b = (sigma_b**2) * np.eye(3) # shape (3, 3)
R_cam = (sigma_cam**2) * np.eye(3) # shape (3, 3)
# ---- ground truth trajectory: sinusoidal motion ----
t_imu = np.linspace(0, T_total, n_imu + 1) # shape (2001,)
p_true = np.zeros((n_imu + 1, 3)) # shape (2001, 3)
v_true = np.zeros((n_imu + 1, 3))
a_true = np.zeros((n_imu + 1, 3))
omega_traj = 0.4 # trajectory frequency (rad/s)
p_true[:, 0] = np.sin(omega_traj * t_imu)
p_true[:, 1] = 0.5 * np.cos(omega_traj * t_imu)
p_true[:, 2] = 0.1 * t_imu
v_true[:, 0] = omega_traj * np.cos(omega_traj * t_imu)
v_true[:, 1] = -0.5 * omega_traj * np.sin(omega_traj * t_imu)
v_true[:, 2] = 0.1 * np.ones(n_imu + 1)
a_true[:, 0] = -omega_traj**2 * np.sin(omega_traj * t_imu)
a_true[:, 1] = -0.5 * omega_traj**2 * np.cos(omega_traj * t_imu)
a_true[:, 2] = np.zeros(n_imu + 1)
# Inject a constant accelerometer bias
b_true = np.array([0.08, -0.05, 0.03]) # shape (3,) -- true bias
# ---- simulate IMU measurements ----
imu_meas = np.zeros((n_imu, 3)) # shape (2000, 3)
for k in range(n_imu):
imu_meas[k] = (a_true[k] + b_true
+ rng.normal(0, sigma_a, 3)) # shape (3,)
# ---- state-space matrices ----
# State: [p(3), v(3), b_a(3)] = 9D
n_state = 9
dt = dt_imu
# Transition matrix F (given a_tilde as control input)
F = np.eye(n_state) # shape (9, 9)
F[0:3, 3:6] = dt * np.eye(3) # p += dt * v
F[0:3, 6:9] = -0.5 * dt**2 * np.eye(3) # p -= dt^2/2 * b_a
F[3:6, 6:9] = -dt * np.eye(3) # v -= dt * b_a
# Control matrix B (maps a_tilde measurement to state)
B = np.zeros((n_state, 3)) # shape (9, 3)
B[0:3, :] = 0.5 * dt**2 * np.eye(3) # p contribution
B[3:6, :] = dt * np.eye(3) # v contribution
# Process noise covariance
Q = np.zeros((n_state, n_state)) # shape (9, 9)
Q[0:3, 0:3] = (0.5 * dt**2)**2 * R_a
Q[3:6, 3:6] = dt**2 * R_a
Q[0:3, 3:6] = 0.5 * dt**3 * R_a
Q[3:6, 0:3] = 0.5 * dt**3 * R_a
Q[6:9, 6:9] = Q_b
# Camera observation matrix (measures position only)
H_cam = np.zeros((3, n_state)) # shape (3, 9)
H_cam[0:3, 0:3] = np.eye(3)
# ---- Standard (covariance-form) EKF ----
x_hat_cov = np.zeros((n_imu + 1, n_state)) # shape (2001, 9)
x_hat_cov[0, :3] = p_true[0] + rng.normal(0, 0.1, 3) # noisy initial position
x_hat_cov[0, 3:6] = v_true[0]
x_hat_cov[0, 6:9] = np.zeros(3) # assume zero initial bias estimate
P_cov = np.diag([0.1**2]*3 + [0.5**2]*3 + [0.1**2]*3) # shape (9, 9)
rmse_cov = np.zeros(n_imu)
rmse_dr = np.zeros(n_imu)
# Dead-reckoning only (no camera updates, no bias)
p_dr = p_true[0].copy()
v_dr = v_true[0].copy()
for k in range(n_imu):
a_input = imu_meas[k] # shape (3,)
# ---- Predict (covariance form) ----
x_pred = F @ x_hat_cov[k] + B @ a_input # shape (9,)
P_pred = F @ P_cov @ F.T + Q # shape (9, 9)
# ---- Dead-reckoning (no filter) ----
p_dr += dt * v_dr + 0.5 * dt**2 * a_input
v_dr += dt * a_input
rmse_dr[k] = np.linalg.norm(p_dr - p_true[k + 1])
# ---- Camera update (every cam_period IMU steps) ----
if (k + 1) % cam_period == 0:
y_cam = p_true[k + 1] + rng.normal(0, sigma_cam, 3) # shape (3,)
S = H_cam @ P_pred @ H_cam.T + R_cam # shape (3, 3)
K = P_pred @ H_cam.T @ np.linalg.inv(S) # shape (9, 3)
nu = y_cam - H_cam @ x_pred # shape (3,)
x_hat_cov[k + 1] = x_pred + K @ nu
P_cov = (np.eye(n_state) - K @ H_cam) @ P_pred
else:
x_hat_cov[k + 1] = x_pred
P_cov = P_pred
rmse_cov[k] = np.linalg.norm(x_hat_cov[k + 1, :3] - p_true[k + 1])
# ---- Information-form filter (same measurements, different update equations) ----
x_hat_inf = np.zeros((n_imu + 1, n_state))
x_hat_inf[0] = x_hat_cov[0].copy()
P0_inf = np.diag([0.1**2]*3 + [0.5**2]*3 + [0.1**2]*3)
Omega = np.linalg.inv(P0_inf) # shape (9, 9)
eta = Omega @ x_hat_inf[0] # shape (9,)
rmse_inf = np.zeros(n_imu)
for k in range(n_imu):
a_input = imu_meas[k]
# ---- Predict (information form: convert, propagate, convert back) ----
P_cur = np.linalg.inv(Omega) # shape (9, 9)
x_cur = np.linalg.solve(Omega, eta) # shape (9,)
x_pred = F @ x_cur + B @ a_input
P_pred = F @ P_cur @ F.T + Q
# ---- Camera update (information form: additive) ----
if (k + 1) % cam_period == 0:
y_cam = p_true[k + 1] + rng.normal(0, sigma_cam, 3)
R_inv = np.linalg.inv(R_cam) # shape (3, 3)
Omega_pred = np.linalg.inv(P_pred)
eta_pred = Omega_pred @ x_pred
# Information update: additive
Omega = Omega_pred + H_cam.T @ R_inv @ H_cam # shape (9, 9)
eta = eta_pred + H_cam.T @ R_inv @ y_cam # shape (9,)
else:
Omega = np.linalg.inv(P_pred)
eta = Omega @ x_pred
x_hat_inf[k + 1] = np.linalg.solve(Omega, eta)
rmse_inf[k] = np.linalg.norm(x_hat_inf[k + 1, :3] - p_true[k + 1])
# ---- Plot ----
t_steps = t_imu[1:] # shape (2000,)
fig, axes = plt.subplots(2, 2, figsize=(13, 9))
# Top-left: 3D trajectory projection (x-y)
ax = axes[0, 0]
ax.plot(p_true[:, 0], p_true[:, 1],
color='#333333', lw=2.0, label='True', zorder=5)
ax.plot(x_hat_cov[:, 0], x_hat_cov[:, 1],
color='#4a90d9', lw=1.5, label='KF estimate', zorder=4)
# Dead-reckoning: recompute trajectory
p_dr_hist = np.zeros((n_imu + 1, 3))
v_dr_hist = np.zeros((n_imu + 1, 3))
p_dr_hist[0] = p_true[0]
v_dr_hist[0] = v_true[0]
for k in range(n_imu):
p_dr_hist[k+1] = p_dr_hist[k] + dt*v_dr_hist[k] + 0.5*dt**2*imu_meas[k]
v_dr_hist[k+1] = v_dr_hist[k] + dt*imu_meas[k]
ax.plot(p_dr_hist[:, 0], p_dr_hist[:, 1],
color='orange', lw=1.2, alpha=0.7, label='Dead-reckoning', zorder=3)
ax.set_xlabel('$x$ (m)')
ax.set_ylabel('$y$ (m)')
ax.legend(fontsize=8)
ax.grid(alpha=0.2)
ax.set_title('Trajectory (x-y view)', fontsize=10)
# Top-right: z vs time
ax = axes[0, 1]
ax.plot(t_imu, p_true[:, 2], color='#333333', lw=2, label='True $z$')
ax.plot(t_imu, x_hat_cov[:, 2], color='#4a90d9', lw=1.5, label='KF $z$')
ax.plot(t_imu, p_dr_hist[:, 2], color='orange', lw=1.2, alpha=0.7, label='DR $z$')
ax.set_xlabel('Time (s)')
ax.set_ylabel('$z$ (m)')
ax.legend(fontsize=8)
ax.grid(alpha=0.2)
ax.set_title('Altitude over time', fontsize=10)
# Bottom-left: position RMSE comparison
ax = axes[1, 0]
ax.semilogy(t_steps, rmse_dr, color='orange', lw=1.5, alpha=0.8, label='Dead-reckoning RMSE')
ax.semilogy(t_steps, rmse_cov, color='#4a90d9', lw=1.5, label='Covariance-form RMSE')
ax.semilogy(t_steps, rmse_inf, color='#2ecc71', lw=1.5, ls='--', label='Info-form RMSE')
ax.set_xlabel('Time (s)')
ax.set_ylabel('Position RMSE (m)')
ax.legend(fontsize=8)
ax.grid(alpha=0.2, which='both')
ax.set_title('RMSE: covariance form vs. information form', fontsize=10)
# Bottom-right: bias estimate convergence
ax = axes[1, 1]
colors_b = ['#4a90d9', '#2ecc71', 'tomato']
axes_labels = ['x', 'y', 'z']
for i in range(3):
ax.plot(t_imu, x_hat_cov[:, 6 + i],
color=colors_b[i], lw=1.5, label=f'Est $b_{{{axes_labels[i]}}}$')
ax.axhline(b_true[i], color=colors_b[i], lw=1.0, ls='--', alpha=0.6,
label=f'True $b_{{{axes_labels[i]}}}$' if i == 0 else None)
ax.axhline(0, color='#333333', lw=0.4, alpha=0.5)
ax.set_xlabel('Time (s)')
ax.set_ylabel('Bias estimate (m/s$^2$)')
ax.legend(fontsize=7, ncol=2)
ax.grid(alpha=0.2)
ax.set_title('Accelerometer bias estimation', fontsize=10)
plt.tight_layout()
plt.show()
print(f"Final position RMSE -- dead-reckoning: {rmse_dr[-1]:.3f} m")
print(f"Final position RMSE -- covariance-form KF: {rmse_cov[-1]:.4f} m")
print(f"Final position RMSE -- information-form KF: {rmse_inf[-1]:.4f} m")
print(f"True bias: {b_true}")
print(f"Est. bias (cov-form, final): {x_hat_cov[-1, 6:9].round(4)}")