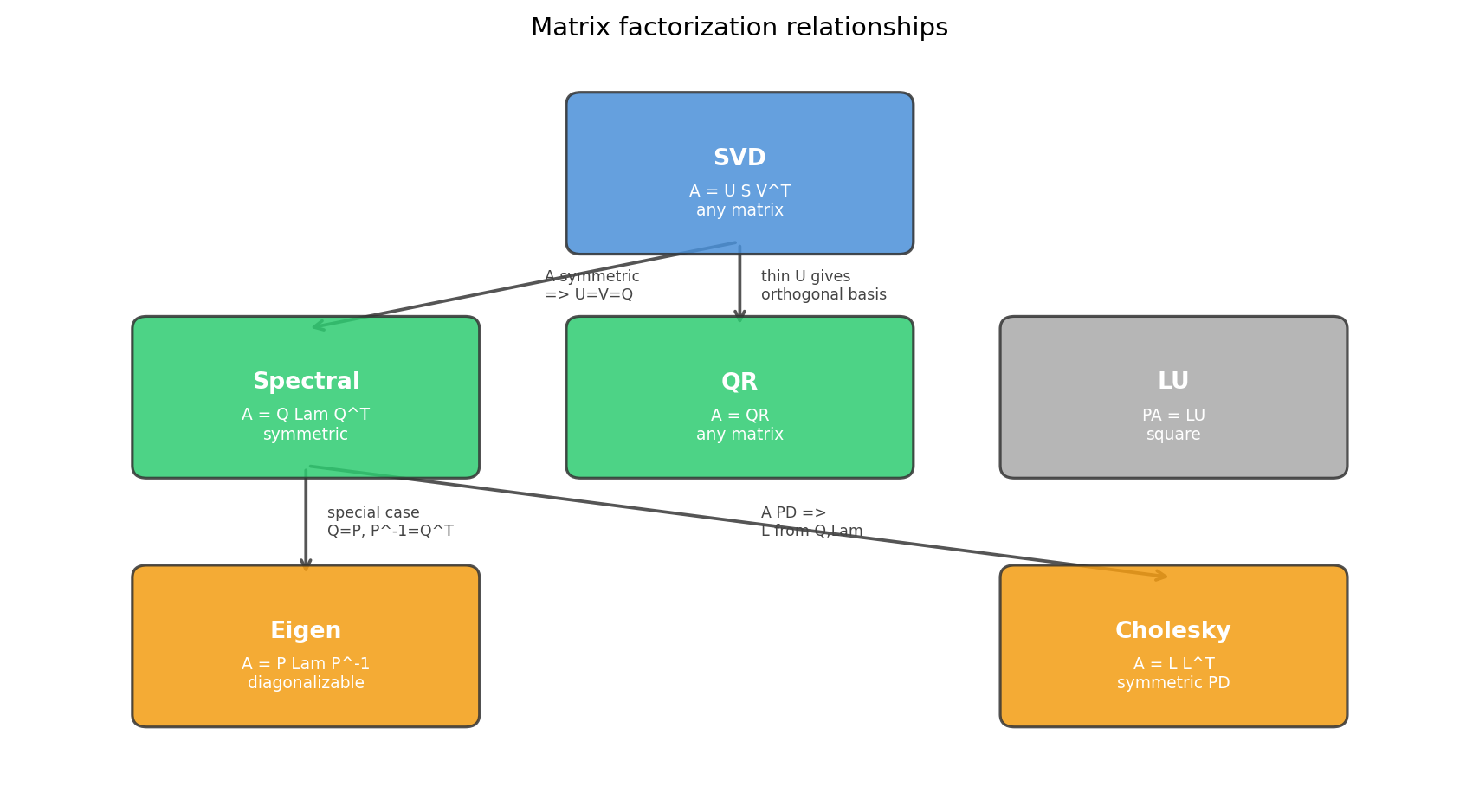
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
fig, ax = plt.subplots(figsize=(9, 5))
ax.set_xlim(0, 10)
ax.set_ylim(0, 6)
ax.axis('off')
nodes = {
'SVD': (5.0, 5.0),
'Spectral': (2.0, 3.2),
'QR': (5.0, 3.2),
'LU': (8.0, 3.2),
'Eigen': (2.0, 1.2),
'Cholesky': (8.0, 1.2),
}
colors = {
'SVD': '#4a90d9',
'Spectral': '#2ecc71',
'QR': '#2ecc71',
'LU': '#aaaaaa',
'Eigen': '#f39c12',
'Cholesky': '#f39c12',
}
descriptions = {
'SVD': 'A = U S V^T\nany matrix',
'Spectral': 'A = Q Lam Q^T\nsymmetric',
'QR': 'A = QR\nany matrix',
'LU': 'PA = LU\nsquare',
'Eigen': 'A = P Lam P^-1\ndiagonalizable',
'Cholesky': 'A = L L^T\nsymmetric PD',
}
for name, (x, y) in nodes.items():
box = mpatches.FancyBboxPatch(
(x - 1.1, y - 0.55), 2.2, 1.1,
boxstyle='round,pad=0.1',
facecolor=colors[name], edgecolor='#333333',
linewidth=1.2, alpha=0.85, zorder=3,
)
ax.add_patch(box)
ax.text(x, y + 0.12, name, ha='center', va='center',
fontsize=10, fontweight='bold', color='white', zorder=4)
ax.text(x, y - 0.22, descriptions[name], ha='center', va='center',
fontsize=7, color='white', zorder=4)
edges = [
('SVD', 'Spectral', 'A symmetric\n=> U=V=Q'),
('SVD', 'QR', 'thin U gives\northogonal basis'),
('Spectral', 'Eigen', 'special case\nQ=P, P^-1=Q^T'),
('Spectral', 'Cholesky', 'A PD =>\nL from Q,Lam'),
]
for src, dst, label in edges:
x0, y0 = nodes[src]
x1, y1 = nodes[dst]
ax.annotate('', xy=(x1, y1 + 0.55), xytext=(x0, y0 - 0.55),
arrowprops=dict(arrowstyle='->', color='#555555', lw=1.4),
zorder=2)
mx, my = (x0 + x1) / 2, (y0 + y1) / 2
ax.text(mx + 0.15, my, label, ha='left', va='center',
fontsize=6.5, color='#444444', zorder=4)
ax.set_title('Matrix factorization relationships', fontsize=11)
plt.tight_layout()
plt.show()