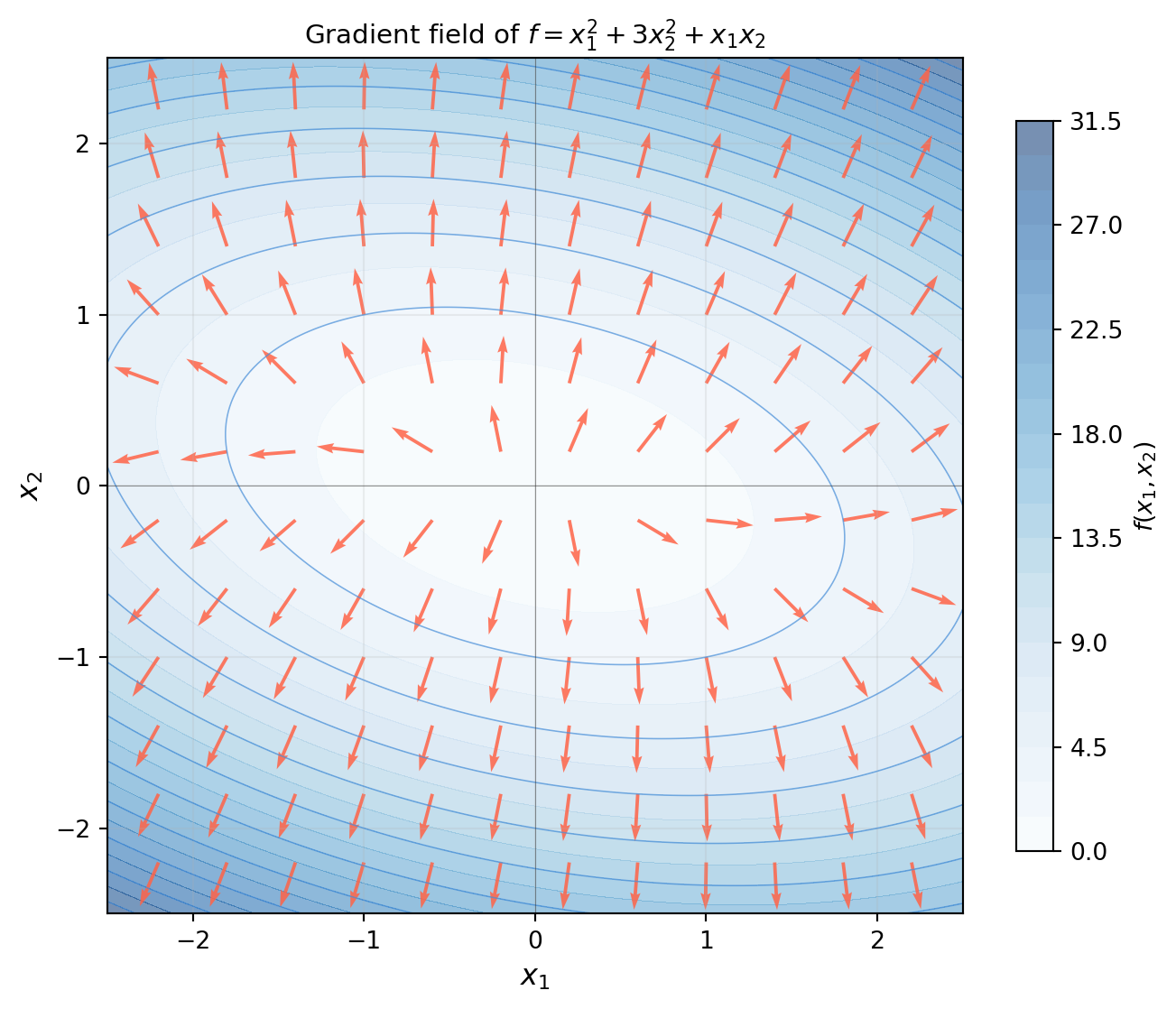
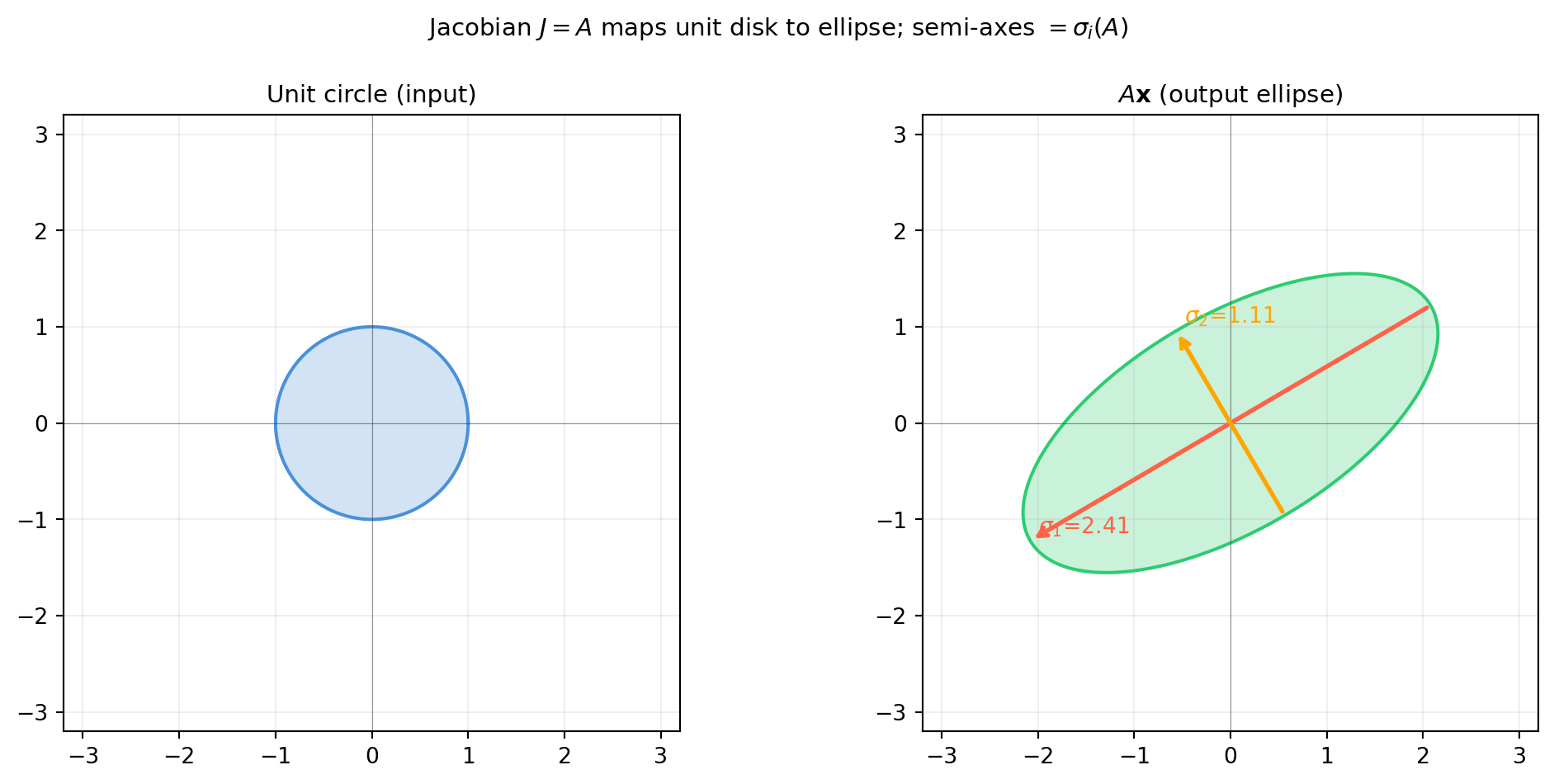
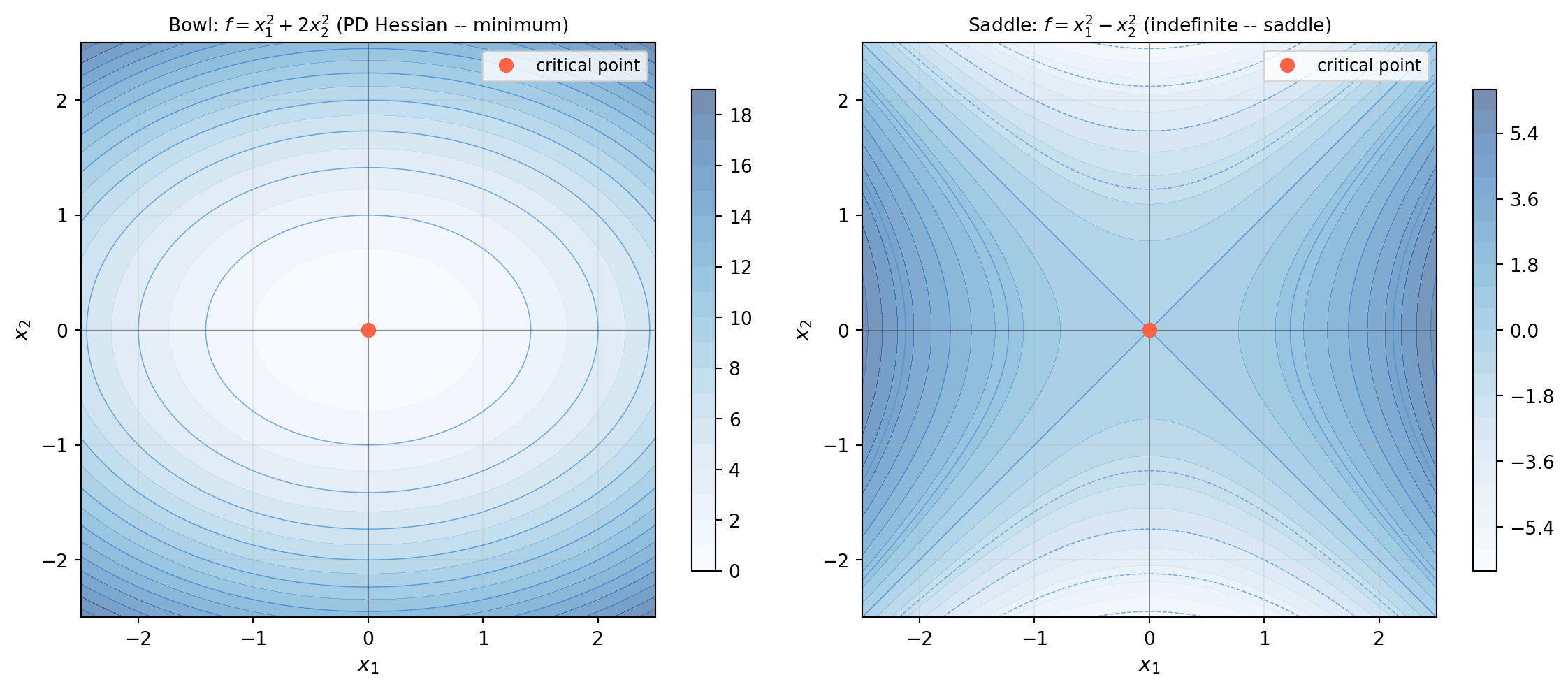
import numpy as np
import matplotlib.pyplot as plt
# Unit circle parametrized by angle
theta = np.linspace(0, 2*np.pi, 500) # shape (500,)
circle = np.vstack([np.cos(theta), np.sin(theta)]) # shape (2, 500)
# A linear map with clear stretching and rotation
A = np.array([[2.0, 0.8],
[0.4, 1.5]]) # shape (2, 2)
ellipse = A @ circle # shape (2, 500) -- Jacobian = A
# SVD to find semi-axes
U, s, Vt = np.linalg.svd(A) # s shape (2,)
V = Vt.T # columns = right singular vectors
fig, axes = plt.subplots(1, 2, figsize=(11, 5))
for ax, pts, title, col in zip(
axes,
[circle, ellipse],
['Unit circle (input)', r'$A\mathbf{x}$ (output ellipse)'],
['#4a90d9', '#2ecc71']
):
ax.fill(pts[0], pts[1], color=col, alpha=0.25)
ax.plot(pts[0], pts[1], color=col, lw=1.5)
ax.axhline(0, color='#333333', lw=0.4, alpha=0.5)
ax.axvline(0, color='#333333', lw=0.4, alpha=0.5)
ax.set_aspect('equal')
ax.set_title(title, fontsize=11)
ax.grid(alpha=0.2)
# Annotate semi-axes on ellipse panel
ax = axes[1]
for i, (si, col_a, lbl) in enumerate(
zip(s, ['tomato', 'orange'], [r'$\sigma_1$', r'$\sigma_2$'])
):
v = U[:, i] # left singular vector (output direction)
ax.annotate('', xy=si*v, xytext=-si*v,
arrowprops=dict(arrowstyle='->', color=col_a, lw=2))
ax.text(*(si*v + np.array([0.08, 0.08])), f'{lbl}={si:.2f}',
fontsize=10, color=col_a)
axes[0].set_xlim(-3.2, 3.2); axes[0].set_ylim(-3.2, 3.2)
axes[1].set_xlim(-3.2, 3.2); axes[1].set_ylim(-3.2, 3.2)
fig.suptitle(r'Jacobian $J=A$ maps unit disk to ellipse; semi-axes $=\sigma_i(A)$',
fontsize=11)
fig.tight_layout()
plt.savefig('ch21-matrix-calculus/fig-jacobian-ellipse.png', dpi=150, bbox_inches='tight')
plt.show()
print(f"Singular values of A: sigma_1={s[0]:.4f}, sigma_2={s[1]:.4f}")
print(f"det(A) = {np.linalg.det(A):.4f} (= sigma_1 * sigma_2 = area scale factor)")