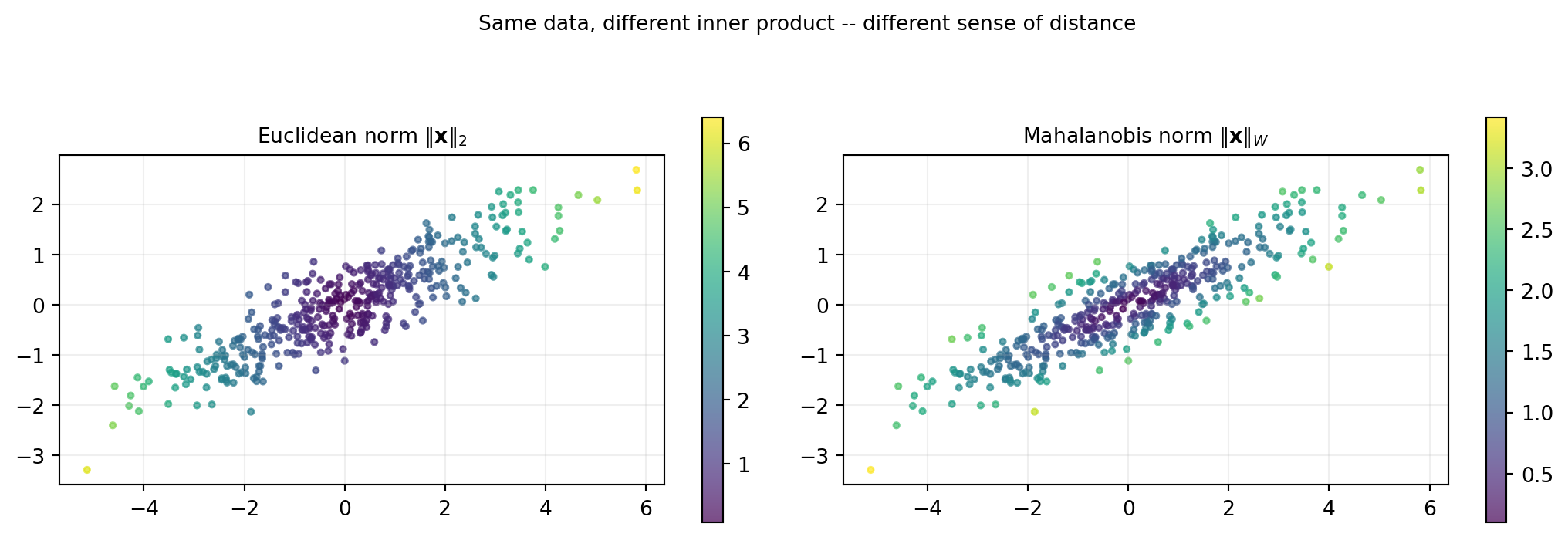
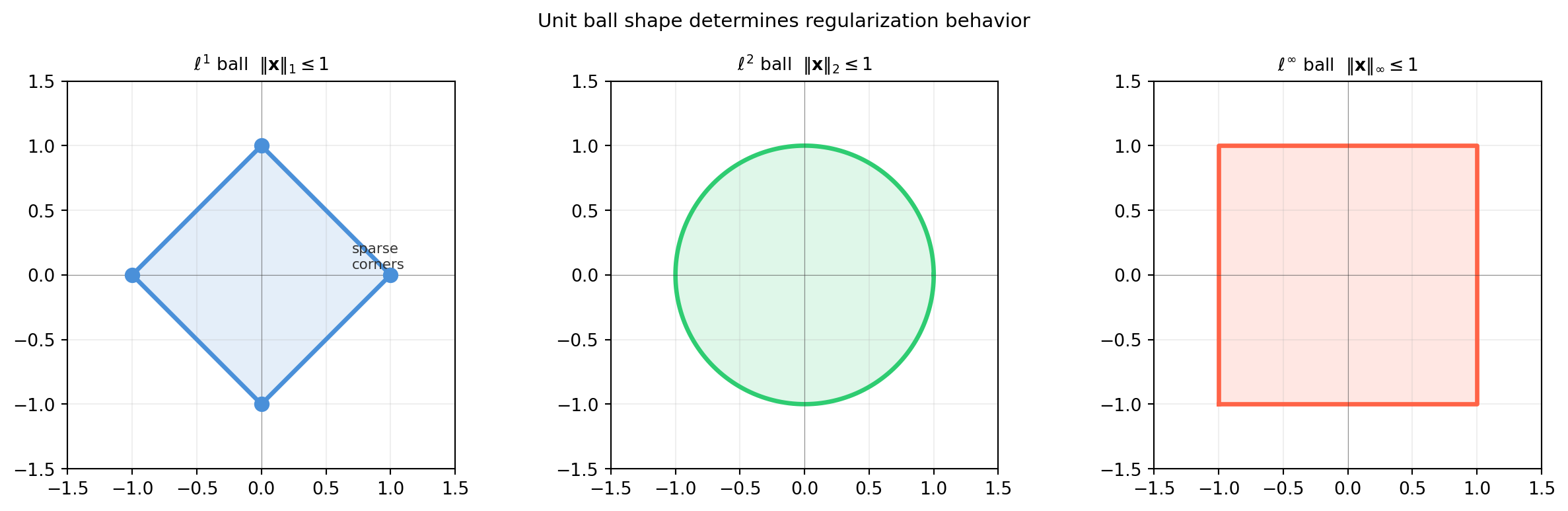
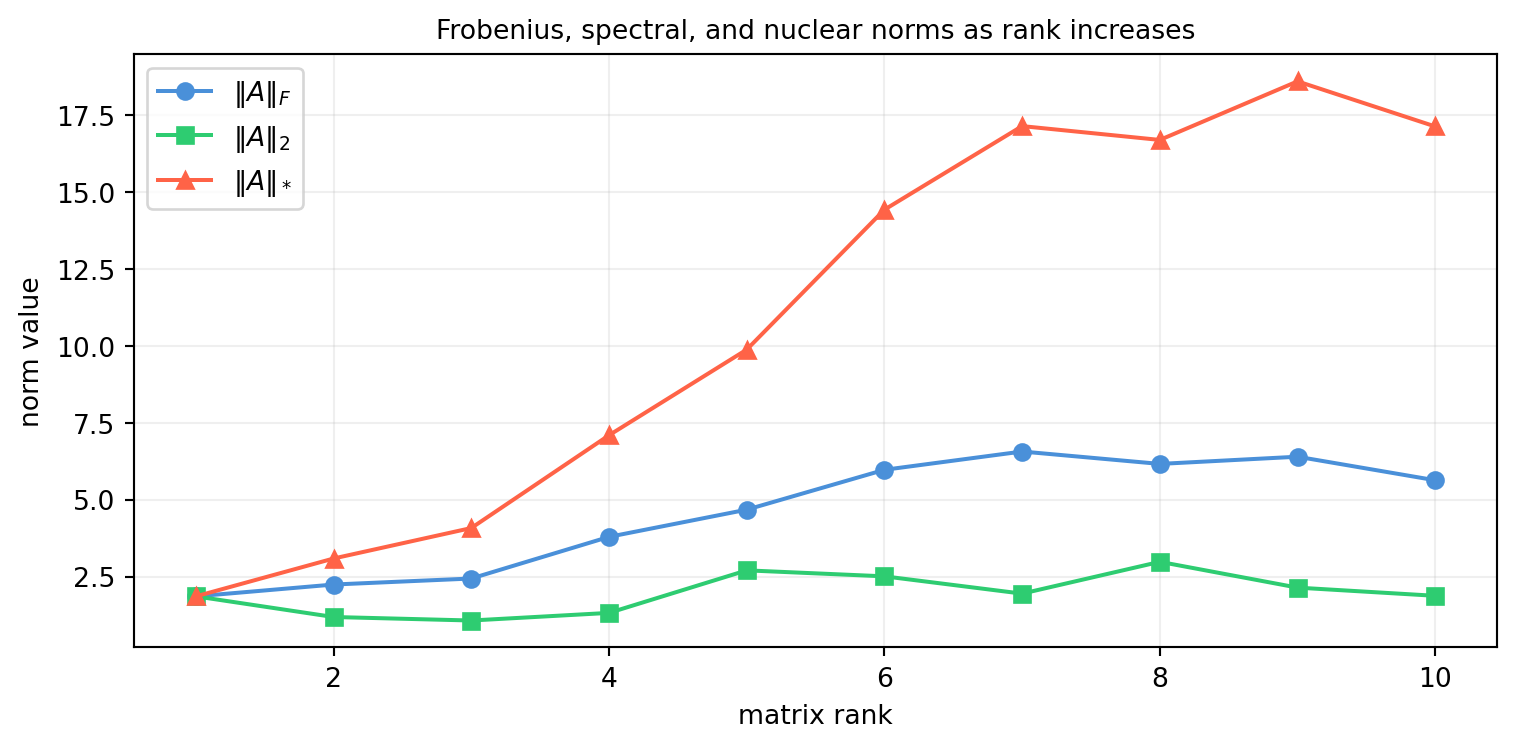
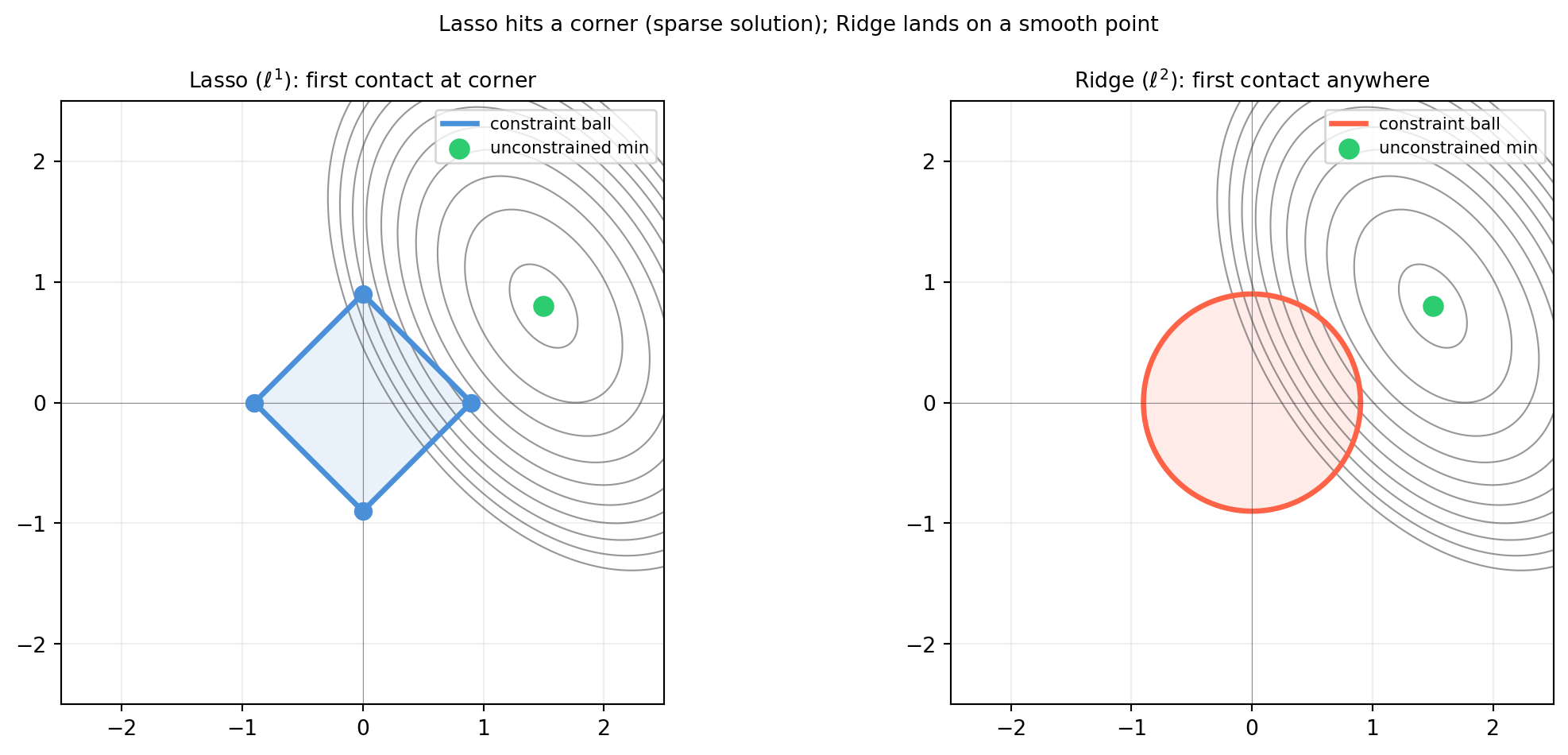
import numpy as np
import matplotlib.pyplot as plt
# Visualize: loss contours meeting the l1 and l2 balls
rng = np.random.default_rng(50)
# True minimum is off-axis
x_true = np.array([1.5, 0.8])
xx, yy = np.meshgrid(np.linspace(-2.5, 2.5, 400),
np.linspace(-2.5, 2.5, 400))
pts = np.stack([xx.ravel(), yy.ravel()], axis=1) # shape (160000, 2)
# Quadratic loss centered at x_true (proxy for Ax=b residual)
A_quad = np.array([[3.0, 1.0], [1.0, 2.0]]) # shape (2, 2)
diff = pts - x_true # shape (160000, 2)
loss = np.einsum('ij,jk,ik->i', diff, A_quad, diff).reshape(400, 400)
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
levels = np.linspace(0.2, 8, 10)
for ax, (ball_type, color, title) in zip(
axes,
[('l1', '#4a90d9', r'Lasso ($\ell^1$): first contact at corner'),
('l2', 'tomato', r'Ridge ($\ell^2$): first contact anywhere')]):
# Loss contours
ax.contour(xx, yy, loss, levels=levels, colors='#333333', alpha=0.5, linewidths=0.8)
# Constraint ball
t = 0.9 # ball radius
theta = np.linspace(0, 2*np.pi, 1000)
if ball_type == 'l1':
bd_pts = np.vstack([np.cos(theta), np.sin(theta)]).T
nrm = np.abs(bd_pts).sum(axis=1)
bd_pts = bd_pts / nrm[:, None] * t
corners = np.array([[t,0],[0,t],[-t,0],[0,-t]])
ax.scatter(corners[:,0], corners[:,1], s=60, color=color, zorder=6)
else:
bd_pts = t * np.vstack([np.cos(theta), np.sin(theta)]).T
ax.plot(bd_pts[:,0], bd_pts[:,1], color=color, lw=2.5, label=f'constraint ball')
ax.fill(bd_pts[:,0], bd_pts[:,1], alpha=0.12, color=color)
ax.scatter(*x_true, s=80, color='#2ecc71', zorder=7, label='unconstrained min')
ax.axhline(0, color='#333333', lw=0.4, alpha=0.5)
ax.axvline(0, color='#333333', lw=0.4, alpha=0.5)
ax.set_xlim(-2.5, 2.5)
ax.set_ylim(-2.5, 2.5)
ax.set_aspect('equal')
ax.grid(True, alpha=0.2)
ax.set_title(title, fontsize=10)
ax.legend(fontsize=8)
plt.suptitle('Lasso hits a corner (sparse solution); Ridge lands on a smooth point',
fontsize=10)
plt.tight_layout()
plt.show()