# Cryptography and Steganography: The Art of Hidden Messages {#sec-crypto}
In 1917, British intelligence decoded a secret telegram from Germany
to Mexico proposing a military alliance against the United States.
Its discovery accelerated American entry into World War I. Three
decades later, Alan Turing and his colleagues at Bletchley Park
cracked the German Enigma machine — an achievement historians
estimate shortened World War II by two years. Today, every time you
type a password or complete a purchase online, you are trusting
mathematics to keep your secret safe from billions of potential
eavesdroppers.
Secret communication falls into two fundamentally different camps.
**Steganography** hides the message so the enemy does not even know
a secret exists — a note concealed inside an image, invisible to
any eye that does not know where to look. **Cryptography** scrambles
the message so that even an enemy who intercepts it cannot read it
without a secret key. Both arts are ancient; both now run on
mathematics.
We begin with the simplest possible cipher — a letter shift that
Julius Caesar used for military dispatches — and build up to the
public-key mathematics that secures the modern internet. Along the
way we will see why ciphers that seemed unbreakable for centuries
fell to a single clever observation, and why the mathematics of
large primes provides security that no ancient cryptographer could
have imagined.
## The Caesar Cipher {#sec-crypto-caesar}
```{python}
#| echo: false
from pathlib import Path; import urllib.request
_d = Path('images'); _d.mkdir(exist_ok=True)
_p = _d / 'caesar.jpg'
if not _p.exists():
_hdr = {'User-Agent': 'Mozilla/5.0 (compatible; QuartoBook/1.0)'}
try:
_req = urllib.request.Request(
'https://upload.wikimedia.org/wikipedia/commons/6/62/Retrato_de_Julio_C%C3%A9sar_%2826724093101%29_%28cropped%29.jpg',
headers=_hdr)
with urllib.request.urlopen(_req, timeout=15) as _r, open(_p, 'wb') as _f:
_f.write(_r.read())
except Exception:
pass
```
::: {.content-visible when-format="pdf"}
```{=latex}
\IfFileExists{images/caesar.jpg}{%
\begin{center}
\begin{minipage}[c]{0.22\textwidth}
\includegraphics[width=\textwidth]{images/caesar.jpg}
\end{minipage}%
\hspace{0.03\textwidth}%
\begin{minipage}[c]{0.35\textwidth}
\small\textit{Julius Caesar (100--44 BCE)}\\[2pt]
\tiny CC BY 2.0, \'{A}ngel M. Felicísimo / Wikimedia Commons
\end{minipage}
\end{center}
}{}
```
:::
::: {.content-visible when-format="html"}
<div style="display:flex; align-items:center; margin:1em 0; gap:12px;">
<img src="images/caesar.jpg" style="width:100px; flex-shrink:0;" alt="Julius Caesar">
<div style="font-size:0.82em;"><em>Julius Caesar (100–44 BCE)</em><br><span style="font-size:0.85em;">CC BY 2.0, Ángel M. Felicísimo / Wikimedia Commons</span></div>
</div>
:::
Julius Caesar, commanding armies in Gaul and fighting a civil war in
Rome, could not trust his messengers. His solution: before sending
any letter, shift every character in the Latin alphabet three
positions forward. A became D, B became E, and so on, with X, Y, Z
wrapping back to A, B, C. A captured messenger could hand over the
tablet and reveal nothing. Only someone who knew the shift could
undo it.
```{python}
import string
def caesar_encrypt(text, shift):
result = []
for ch in text.upper():
if ch.isalpha():
offset = ord(ch) - ord('A')
enc = (offset + shift) % 26
result.append(chr(enc + ord('A')))
else:
result.append(ch)
return ''.join(result)
def caesar_decrypt(text, shift):
return caesar_encrypt(text, 26 - shift)
msg = "MATHEMATICS IS THE LANGUAGE OF NATURE"
enc = caesar_encrypt(msg, 3)
dec = caesar_decrypt(enc, 3)
print("Original: ", msg)
print("Encrypt: ", enc)
print("Decrypt: ", dec)
```
Every letter is shifted by exactly 3, and the decryption shifts back
by $26 - 3 = 23$ — or equivalently, $-3 \bmod 26$. There are only
26 possible keys (shifts 0 through 25), so even without mathematics,
an attacker who tries all 26 will find the message in seconds.
But there is a subtler attack that works even without trying every
key.
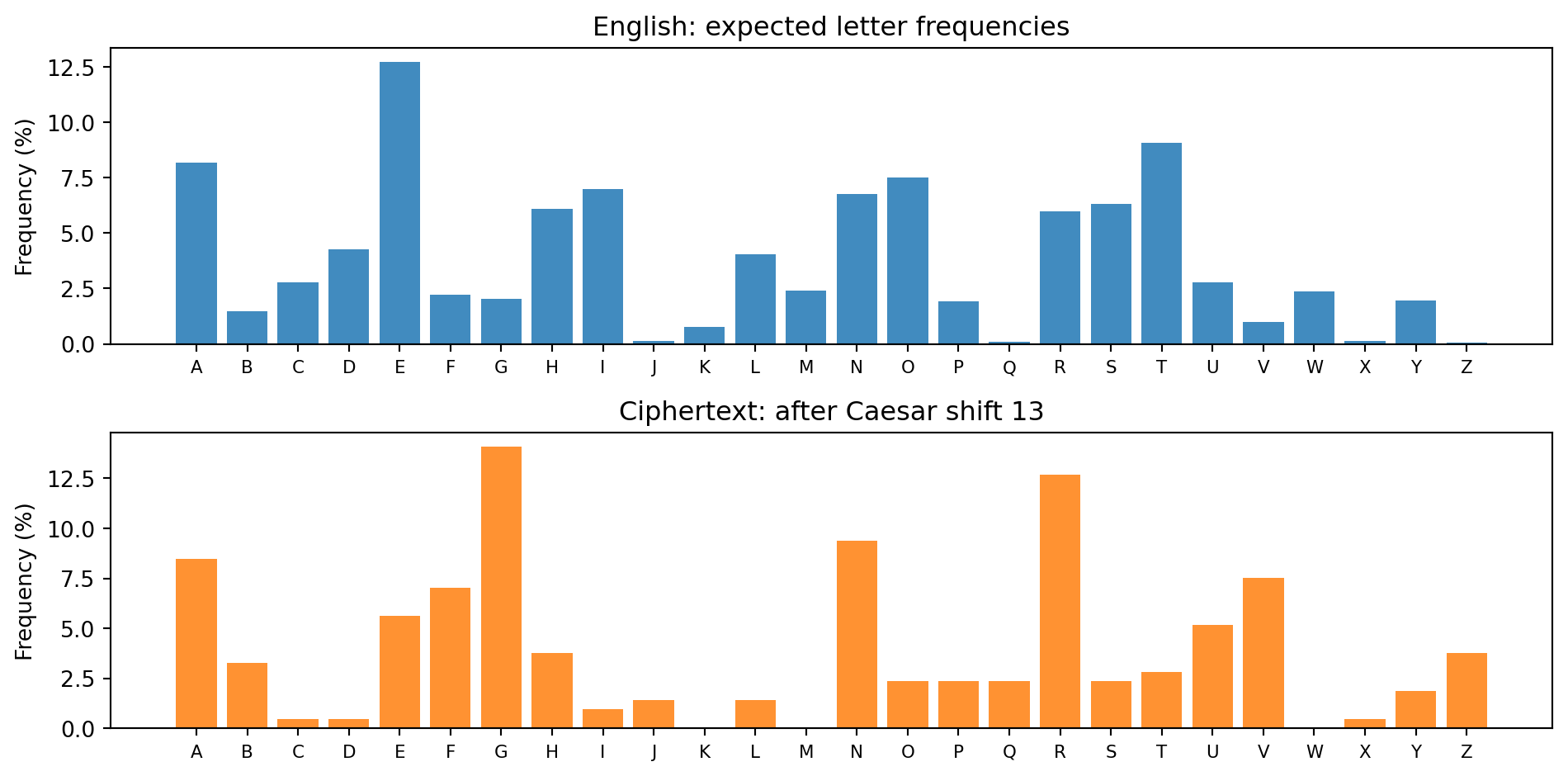
### Research Example: Can Letter Frequencies Crack a Caesar Cipher? {.unnumbered .unlisted}
In English, the letter E appears in roughly 12.7% of all text, T in
about 9.1%, A in about 8.2%. These frequencies are so stable that
even in a randomly chosen paragraph from any English novel, E will
almost certainly be the most common letter. A Caesar cipher preserves
these frequencies — it just shifts which letter *looks* most common.
If we encrypt a long English text with a Caesar cipher of shift $k$,
the most common letter in the ciphertext will be the encryption of E,
namely the letter $k$ steps after E in the alphabet. So the
**key $k$ = (position of most common ciphertext letter) $-$ (position
of E), mod 26**.
```{python}
# uses: caesar_encrypt()
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter
import string
# Standard English letter frequencies (percent)
ENG_FREQ = {
'A': 8.17, 'B': 1.49, 'C': 2.78, 'D': 4.25,
'E': 12.70, 'F': 2.23, 'G': 2.02, 'H': 6.09,
'I': 6.97, 'J': 0.15, 'K': 0.77, 'L': 4.03,
'M': 2.41, 'N': 6.75, 'O': 7.51, 'P': 1.93,
'Q': 0.10, 'R': 5.99, 'S': 6.33, 'T': 9.06,
'U': 2.76, 'V': 0.98, 'W': 2.36, 'X': 0.15,
'Y': 1.97, 'Z': 0.07
}
sample = (
"WHAT IS MATHEMATICS AT ITS BEST BUT AN ART "
"OF GIVING THE SAME NAME TO DIFFERENT THINGS "
"THE EQUATION IS NOT MERELY A FORMULA BUT A "
"LENS THAT BRINGS HIDDEN STRUCTURE INTO FOCUS "
"AND EVERY GREAT SECRET LIES WAITING IN THE "
"PATTERNS THAT NUMBERS MAKE WHEN THEY DANCE"
)
shift = 13
ciphertext = caesar_encrypt(sample, shift)
letters = list(string.ascii_uppercase)
counts = Counter(c for c in ciphertext if c.isalpha())
total = sum(counts.values())
obs = [100 * counts.get(l, 0) / total for l in letters]
exp = [ENG_FREQ[l] for l in letters]
BLUE = '#1f77b4'
ORANGE = '#ff7f0e'
x = np.arange(26)
fig, axes = plt.subplots(2, 1, figsize=(10, 5))
axes[0].bar(x, exp, color=BLUE, alpha=0.85)
axes[0].set_xticks(x)
axes[0].set_xticklabels(letters, fontsize=8)
axes[0].set_ylabel('Frequency (%)')
axes[0].set_title('English: expected letter frequencies')
axes[1].bar(x, obs, color=ORANGE, alpha=0.85)
axes[1].set_xticks(x)
axes[1].set_xticklabels(letters, fontsize=8)
axes[1].set_ylabel('Frequency (%)')
axes[1].set_title(
f'Ciphertext: after Caesar shift {shift}')
fig.tight_layout()
plt.show()
```
The two charts are identical in *shape* — the same hills and valleys
— but shifted left by 13 positions. E's tall bar has become R's tall
bar. Finding the shift is as easy as asking: how far did the tallest
bar move?
```{python}
# uses: counts, ciphertext, caesar_decrypt()
# Crack the cipher: find the shift
# that makes the most common letter map to E
most_common = counts.most_common(1)[0][0]
crack_shift = (ord(most_common) - ord('E')) % 26
cracked = caesar_decrypt(ciphertext, crack_shift)
print(f"Most common letter in ciphertext: {most_common}")
print(f"Guessed shift: {crack_shift}")
print("Decrypted:", cracked[:50])
```
The Caesar cipher falls completely to frequency analysis. You do not
even need a computer: al-Kindi, a ninth-century Arab scholar, described
this method around 800 CE, over a thousand years before anyone
computerized it. The cipher Julius Caesar trusted with military secrets
can be cracked with pencil and paper in a few minutes.
```{python}
#| echo: false
from pathlib import Path; import urllib.request
_d = Path('images'); _d.mkdir(exist_ok=True)
_p = _d / 'alkindi_ms.png'
if not _p.exists():
try: urllib.request.urlretrieve('https://upload.wikimedia.org/wikipedia/commons/7/76/Al-kindi_cryptographic.png', _p)
except Exception: pass
```
::: {.content-visible when-format="pdf"}
```{=latex}
\IfFileExists{images/alkindi_ms.png}{%
\begin{center}
\begin{minipage}[c]{0.22\textwidth}
\includegraphics[width=\textwidth]{images/alkindi_ms.png}
\end{minipage}%
\hspace{0.03\textwidth}%
\begin{minipage}[c]{0.35\textwidth}
\small\textit{Al-Kindi's cryptographic manuscript (c.\ 850 CE)}\\[2pt]
\tiny Public domain, via Wikimedia Commons
\end{minipage}
\end{center}
}{}
```
:::
::: {.content-visible when-format="html"}
<div style="display:flex; align-items:center; margin:1em 0; gap:12px;">
<img src="images/alkindi_ms.png" style="width:100px; flex-shrink:0;" alt="Al-Kindi cryptographic manuscript">
<div style="font-size:0.82em;"><em>Al-Kindi's cryptographic manuscript (c. 850 CE)</em><br><span style="font-size:0.85em;">Public domain, via Wikimedia Commons</span></div>
</div>
:::
## The Vigenère Cipher {#sec-crypto-vigenere}
```{python}
#| echo: false
from pathlib import Path; import urllib.request
_d = Path('images'); _d.mkdir(exist_ok=True)
_p = _d / 'vigenere.jpg'
if not _p.exists():
_hdr = {'User-Agent': 'Mozilla/5.0 (compatible; QuartoBook/1.0)'}
try:
_req = urllib.request.Request(
'https://upload.wikimedia.org/wikipedia/commons/b/bd/Blaise_de_Vigenere..._%28BM_1869%2C0612.200%29.jpg',
headers=_hdr)
with urllib.request.urlopen(_req, timeout=15) as _r, open(_p, 'wb') as _f:
_f.write(_r.read())
except Exception:
pass
```
::: {.content-visible when-format="pdf"}
```{=latex}
\IfFileExists{images/vigenere.jpg}{%
\begin{center}
\begin{minipage}[c]{0.22\textwidth}
\includegraphics[width=\textwidth]{images/vigenere.jpg}
\end{minipage}%
\hspace{0.03\textwidth}%
\begin{minipage}[c]{0.35\textwidth}
\small\textit{Blaise de Vigen\`{e}re (1523--1596)}\\[2pt]
\tiny Public domain, British Museum / Wikimedia Commons
\end{minipage}
\end{center}
}{}
```
:::
::: {.content-visible when-format="html"}
<div style="display:flex; align-items:center; margin:1em 0; gap:12px;">
<img src="images/vigenere.jpg" style="width:100px; flex-shrink:0;" alt="Blaise de Vigenère">
<div style="font-size:0.82em;"><em>Blaise de Vigenère (1523–1596)</em><br><span style="font-size:0.85em;">Public domain, British Museum / Wikimedia Commons</span></div>
</div>
:::
The Caesar cipher is easy to break because it uses the *same* shift
for every letter. What if the shift changed with every letter? In the
1550s the French diplomat Blaise de Vigenère popularized a cipher
that used a *keyword* to choose a different shift for each position.
The keyword cycles: if the key is MATH, the first letter is shifted
by M=12, the second by A=0, the third by T=19, the fourth by H=7,
then back to M=12 for the fifth, and so on.
```{python}
def vigenere_encrypt(text, key):
result = []
key = key.upper()
ki = 0
for ch in text.upper():
if ch.isalpha():
shift = ord(key[ki % len(key)]) - ord('A')
enc = (ord(ch) - ord('A') + shift) % 26
result.append(chr(enc + ord('A')))
ki += 1
else:
result.append(ch)
return ''.join(result)
def vigenere_decrypt(text, key):
result = []
key = key.upper()
ki = 0
for ch in text.upper():
if ch.isalpha():
shift = ord(key[ki % len(key)]) - ord('A')
dec = (ord(ch) - ord('A') - shift) % 26
result.append(chr(dec + ord('A')))
ki += 1
else:
result.append(ch)
return ''.join(result)
msg = "MATHEMATICS IS THE LANGUAGE OF NATURE"
key = "MATH"
enc = vigenere_encrypt(msg, key)
dec = vigenere_decrypt(enc, key)
print("Original: ", msg)
print("Key: ", key * (len(msg) // len(key) + 1))
print("Encrypted:", enc)
print("Decrypted:", dec)
```
The same letter E appears as different ciphertext letters depending
on its position: sometimes as Q (shift M=12), sometimes as E itself
(shift A=0), sometimes as X (shift T=19). Frequency analysis now sees
a flatter distribution — the tall E bar is spread across multiple
positions. For three centuries this cipher was known as *le chiffre
indéchiffrable* — the unbreakable cipher.
## The Kasiski Test: Cracking the Unbreakable {#sec-crypto-kasiski}
Friedrich Kasiski, a Prussian infantry officer, published a
pamphlet in 1863 [@kasiski1863] that broke the unbreakable. His
observation was elegantly simple: if the same segment of plaintext
happens to line up with the same segment of the key, it will produce
the same segment of ciphertext. So **repeated patterns in the
ciphertext reveal the key length**. Find the distances between
repeated three-letter groups in the ciphertext, take their greatest
common divisor, and you likely have the key length — or a multiple of
it. Once you know the key length $k$, you split the ciphertext into
$k$ streams (every $k$-th letter), and each stream is just a Caesar
cipher, breakable by frequency analysis.
But Kasiski needed a specific coincidence of plaintext meeting key.
A cleaner method, developed decades later, uses the **Index of
Coincidence (IoC)**: the probability that two randomly chosen letters
from a text are the same.
$$\text{IoC} = \frac{\sum_{i=A}^{Z} n_i(n_i - 1)}{N(N-1)}$$
where $n_i$ is the count of letter $i$ and $N$ is the total number
of letters. For English prose, IoC $\approx 0.065$ because the
language is uneven (E is much more common than Z). For purely random
text, IoC $\approx 0.038$ (each of 26 letters equally likely).
A Vigenère cipher with key length $k$ mixes $k$ different Caesar
ciphers. Each individual stream is still "English-shaped" (high IoC),
but when you look at all streams together the distribution flattens.
As the key grows longer, the IoC of the ciphertext approaches that
of random text.
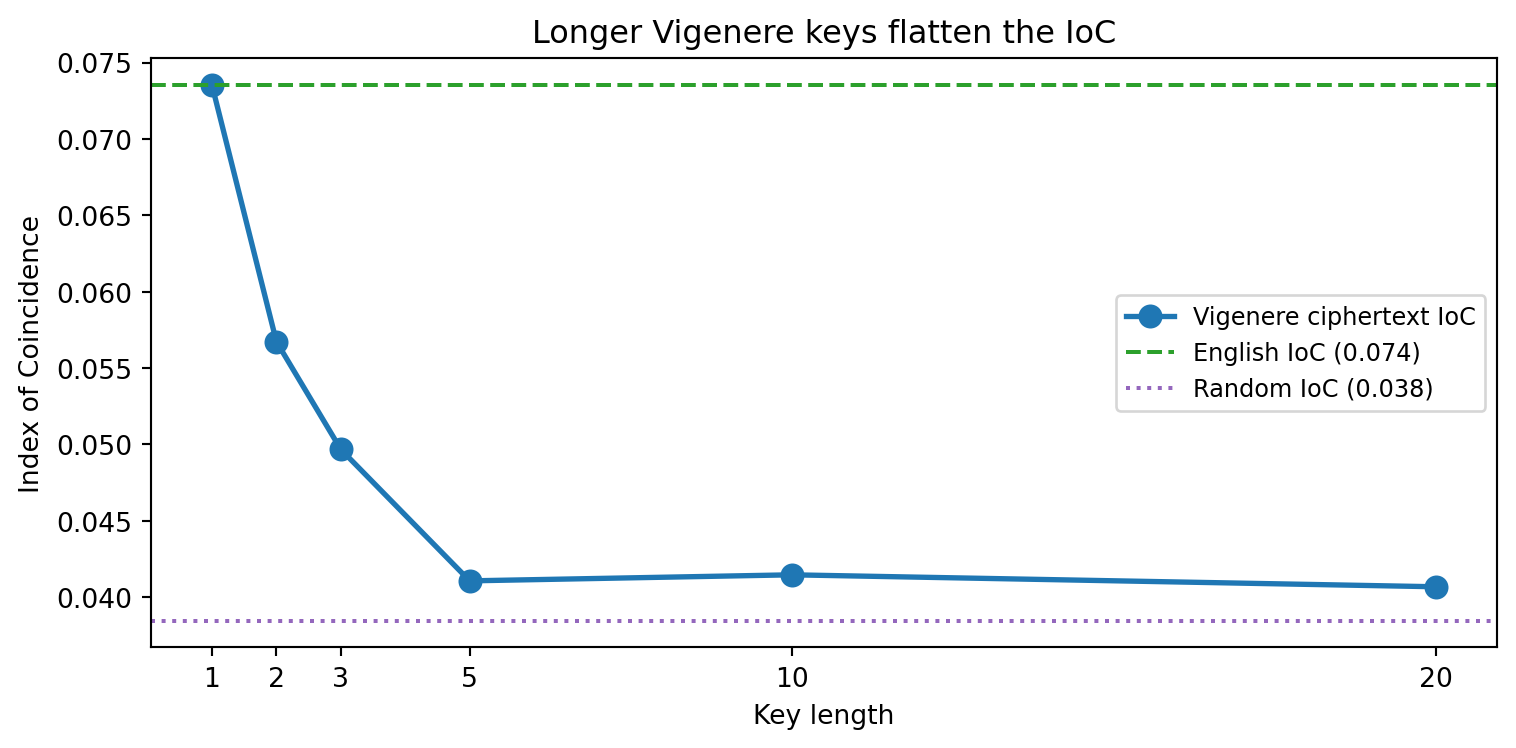
### Research Example: Does Key Length Flatten the Letter Distribution? {.unnumbered .unlisted}
We encrypt the same 2000-character English passage with Vigenère
keys of length 1, 2, 3, 5, 10, and 20, then measure the IoC. A
key of length 1 is just Caesar — IoC stays at the English level.
As the key grows, IoC drops toward the random baseline.
```{python}
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter
# ~2000 chars of English text (repeated to fill length)
PLAIN = (
"THE SECRET OF GETTING AHEAD IS GETTING STARTED "
"THE SECRET OF GETTING STARTED IS BREAKING YOUR "
"COMPLEX OVERWHELMING TASKS INTO SMALL MANAGEABLE "
"TASKS AND THEN STARTING ON THE FIRST ONE NUMBERS "
"AND PATTERNS ARE THE HIDDEN LANGUAGE OF NATURE "
"MATHEMATICS IS NOT ABOUT NUMBERS EQUATIONS "
"COMPUTATIONS OR ALGORITHMS IT IS ABOUT UNDERSTANDING"
)
# Repeat to get a longer passage
plain = (PLAIN * 5)[:2000].replace(" ", "")
def index_of_coincidence(text):
counts = Counter(text)
N = len(text)
if N < 2:
return 0.0
return sum(
n * (n - 1) for n in counts.values()
) / (N * (N - 1))
import random
random.seed(42)
alphabet = list(string.ascii_uppercase)
key_lengths = [1, 2, 3, 5, 10, 20]
ioc_vals = []
for klen in key_lengths:
key = ''.join(
random.choices(alphabet, k=klen))
ct = vigenere_encrypt(plain, key)
ioc_vals.append(index_of_coincidence(ct))
eng_ioc = index_of_coincidence(plain)
rand_ioc = 1 / 26 # theoretical random
BLUE = '#1f77b4'
GREEN = '#2ca02c'
PURPLE = '#9467bd'
fig, ax = plt.subplots(figsize=(8, 4))
ax.plot(key_lengths, ioc_vals, 'o-',
color=BLUE, lw=2, ms=8,
label='Vigenere ciphertext IoC')
ax.axhline(eng_ioc, color=GREEN,
ls='--', lw=1.5,
label=f'English IoC ({eng_ioc:.3f})')
ax.axhline(rand_ioc, color=PURPLE,
ls=':', lw=1.5,
label=f'Random IoC ({rand_ioc:.3f})')
ax.set_xlabel('Key length')
ax.set_ylabel('Index of Coincidence')
ax.set_title(
'Longer Vigenere keys flatten the IoC')
ax.legend(fontsize=9)
ax.set_xticks(key_lengths)
fig.tight_layout()
plt.show()
```
The curve falls from English-level IoC (key length 1 = Caesar) down
toward the random baseline as the key lengthens. An attacker uses
this in reverse: try key lengths 1, 2, 3, ... and split the
ciphertext into that many streams. For the true key length, each
stream will have a high IoC (it is just Caesar-encrypted English).
For wrong key lengths, streams will mix letters from different Caesar
shifts and look more random. The true key length jumps out of the
data.
Claude Shannon proved in 1949 that the *only* unbreakable cipher is
one where the key is as long as the message and used exactly once —
the **one-time pad** [@shannon1949]. Any cipher with a shorter
repeating key, no matter how clever, leaks statistical information
that a careful analyst can exploit.
## Steganography: Hidden in Plain Sight {#sec-crypto-stego}
Cryptography scrambles a message so it cannot be read; steganography
hides it so it cannot be seen. A cryptographic message shouts "I
have a secret!" to anyone who intercepts it — it is obviously
ciphertext. A steganographic message whispers "I am just an ordinary
photograph" while secretly carrying a payload invisible to human
eyes.
The most powerful modern steganography technique exploits the
**Least Significant Bit (LSB)** of digital images. Every pixel in a
color image stores three numbers between 0 and 255: red, green, and
blue intensity. The number 200 in binary is `11001000`. The LSB is
that final `0`. Flipping it to `1` gives `11001001` = 201 — a
difference of one gray level out of 256. The human eye cannot see a
difference of one unit in brightness. But we can use that hidden bit
to carry a message.
```{python}
import numpy as np
# Build a colorful gradient image with numpy only
H, W = 200, 300
row = np.linspace(0, 1, H)
col = np.linspace(0, 1, W)
R = (np.outer(row, np.ones(W)) * 200
+ 55).astype(np.uint8)
G = (np.outer(np.ones(H), col) * 160
+ 70).astype(np.uint8)
B = ((np.outer(row, col) + 0.3)
* 150).clip(0, 255).astype(np.uint8)
original = np.stack([R, G, B], axis=-1)
def text_to_bits(text):
"""Convert ASCII text to a list of bits."""
bits = []
for ch in text:
byte = ord(ch)
for i in range(7, -1, -1):
bits.append((byte >> i) & 1)
bits += [0] * 8 # null terminator
return bits
def lsb_hide(image, message):
"""Encode message in LSBs of red channel."""
img = image.copy()
bits = text_to_bits(message)
flat = img[:, :, 0].flatten()
for i, bit in enumerate(bits):
flat[i] = (flat[i] & 0xFE) | bit
img[:, :, 0] = flat.reshape(H, W)
return img
def lsb_extract(image):
"""Decode message hidden in LSBs."""
flat = image[:, :, 0].flatten()
chars = []
for i in range(0, len(flat) - 7, 8):
byte_val = 0
for j in range(8):
byte_val = (byte_val << 1) | (flat[i+j] & 1)
if byte_val == 0:
break
chars.append(chr(byte_val))
return ''.join(chars)
from mpmath import mp
mp.dps = 1010 # extra digits for rounding safety
# 1001 significant figures gives "3." + 1000 decimal digits
secret = mp.nstr(mp.pi, 1001, strip_zeros=False)
stego = lsb_hide(original, secret)
recovered = lsb_extract(stego)
# width=60 wraps long output to fit the printed page
import textwrap
print(f"Hiding {len(secret)} characters ({len(secret)-2} decimal")
print("digits of pi) inside the image ...")
print()
print("First 60 characters recovered:")
print(textwrap.fill(recovered[:60], width=60))
print()
print(f"Match: {recovered == secret}")
```
### Research Example: Can You Spot 1,000 Digits of Pi? {.unnumbered .unlisted}
The two images below contain identical pixel values *almost*
everywhere. The differences are in the least-significant bits of
a narrow band of pixels in the upper-left corner — the 1,002
characters that spell out pi to 1,000 decimal places. The third
panel amplifies those differences by 255 to make them visible.
```{python}
# uses: original, stego
import matplotlib.pyplot as plt
import numpy as np
diff = np.abs(
original.astype(np.int16)
- stego.astype(np.int16))
# Only LSB changed per pixel: diff is 0 or 1.
# Multiply by 255 to make modified pixels bright.
diff_vis = (diff[:, :, 0] * 255).astype(np.uint8)
fig, axes = plt.subplots(1, 3, figsize=(11, 3.5))
axes[0].imshow(original)
axes[0].set_title('Original image')
axes[0].axis('off')
axes[1].imshow(stego)
axes[1].set_title(
'1,000 digits of pi hidden inside\n(looks identical)')
axes[1].axis('off')
im = axes[2].imshow(
diff_vis, cmap='viridis', vmin=0, vmax=255)
axes[2].set_title(
'Modified pixels (magnified x255)')
axes[2].axis('off')
plt.colorbar(im, ax=axes[2],
fraction=0.046, pad=0.04)
fig.tight_layout()
plt.show()
```
The left two panels are visually indistinguishable. The right panel
reveals exactly which pixels were modified: a band of 8,016 pixels
(1,002 characters × 8 bits each) out of 60,000, covering roughly
13% of the red channel. An eavesdropper who intercepts the image
sees only a gradient photograph. The 1,000-digit constant they
cannot read is riding invisibly inside it.
A full 12-megapixel photograph (4000 × 3000 pixels × 3 channels)
could hide roughly 1.3 megabytes of text in its LSBs — an entire
novel — with no visible change to the image.
```{python}
#| echo: false
from pathlib import Path; import urllib.request
_d = Path('images'); _d.mkdir(exist_ok=True)
_p = _d / 'thumb_TWEXCYQKyDc.jpg'
try:
if not _p.exists():
urllib.request.urlretrieve(
'https://img.youtube.com/vi/'
'TWEXCYQKyDc/0.jpg', _p)
except Exception:
pass
```
::: {.content-visible when-format="pdf"}
```{=latex}
\begin{center}
\begin{minipage}[c]{0.28\textwidth}
\centering
\href{https://youtu.be/TWEXCYQKyDc}{\includegraphics[width=\textwidth]{images/thumb_TWEXCYQKyDc.jpg}}
\end{minipage}%
\hspace{0.02\textwidth}%
\begin{minipage}[c]{0.28\textwidth}
\small\textbf{Computerphile}\\[3pt]
\small Secrets Hidden in Images (Steganography)\\[3pt]
\small\href{https://youtu.be/TWEXCYQKyDc}{\texttt{youtu.be/TWEXCYQKyDc}}
\end{minipage}%
\hspace{0.02\textwidth}%
\begin{minipage}[c]{0.36\textwidth}
\small Dr Mike Pound shows how to hide secret messages inside ordinary images, and how to detect them.
\end{minipage}
\end{center}
```
:::
::: {.content-visible when-format="html"}
<div style="display:flex; align-items:flex-start; margin:1em 0; gap:12px; width:100%;">
<div style="flex:0 0 200px;"><a href="https://youtu.be/TWEXCYQKyDc" target="_blank"><img src="https://img.youtube.com/vi/TWEXCYQKyDc/0.jpg" style="width:100%;display:block;" alt="Secrets Hidden in Images (Steganography)"></a></div>
<div style="flex:1; font-size:0.85em;"><strong>Computerphile</strong><br>Secrets Hidden in Images (Steganography)<br><a href="https://youtu.be/TWEXCYQKyDc" target="_blank" style="font-family:Consolas,monospace;">youtu.be/TWEXCYQKyDc</a></div>
<div style="flex:1; font-size:0.85em;">Dr Mike Pound shows how to hide secret messages inside ordinary images, and how to detect them.</div>
</div>
:::
## The Key Exchange Problem {#sec-crypto-dh}
```{python}
#| echo: false
from pathlib import Path; import urllib.request
_d = Path('images'); _d.mkdir(exist_ok=True)
_p = _d / 'diffie.jpg'
if not _p.exists():
try: urllib.request.urlretrieve('https://upload.wikimedia.org/wikipedia/commons/0/0c/Whitfield_Diffie_Royal_Society.jpg', _p)
except Exception: pass
```
::: {.content-visible when-format="pdf"}
```{=latex}
\IfFileExists{images/diffie.jpg}{%
\begin{center}
\begin{minipage}[c]{0.22\textwidth}
\includegraphics[width=\textwidth]{images/diffie.jpg}
\end{minipage}%
\hspace{0.03\textwidth}%
\begin{minipage}[c]{0.35\textwidth}
\small\textit{Whitfield Diffie (b.\ 1944), co-inventor of public-key cryptography}\\[2pt]
\tiny CC BY-SA 4.0, Duncan.Hull / The Royal Society, via Wikimedia Commons
\end{minipage}
\end{center}
}{}
```
:::
::: {.content-visible when-format="html"}
<div style="display:flex; align-items:center; margin:1em 0; gap:12px;">
<img src="images/diffie.jpg" style="width:100px; flex-shrink:0;" alt="Whitfield Diffie">
<div style="font-size:0.82em;"><em>Whitfield Diffie (b. 1944), co-inventor of public-key cryptography</em><br><span style="font-size:0.85em;">CC BY-SA 4.0, Duncan.Hull / The Royal Society, via Wikimedia Commons</span></div>
</div>
:::
Both parties in a secret conversation need to agree on a shared key.
But how do you agree on a key when every message is intercepted?
This sounds paradoxical — and for most of human history, it *was*
paradoxical. You had to meet in person to exchange the key, or use
a trusted courier. Every wartime codebook had to be physically
transported before communications could begin.
In 1976, Whitfield Diffie and Martin Hellman shattered this
assumption [@diffie1976new]. They showed that two strangers can
agree on a shared secret over a completely public channel — even
with an eavesdropper reading every message — using a mathematical
trick with modular exponentiation.
**The paint-mixing analogy:** Imagine Alice and Bob agree publicly on
a common paint color — say, yellow. Alice secretly mixes in her own
private color (blue) and sends Bob the result (green). Bob secretly
mixes in his private color (red) and sends Alice the result (orange).
Now: Alice takes Bob's orange mixture and adds her secret blue →
gets a brown. Bob takes Alice's green mixture and adds his secret
red → gets the *same* brown. They share a secret color neither one
transmitted, and Eve, who intercepted only yellow, green, and orange,
cannot unmix colors to find Alice's blue or Bob's red.
The mathematics works exactly the same way — with modular
exponentiation as the "one-way mixing" operation. Choose a prime $p$
and a **generator** $g$ (a primitive root mod $p$). These are public.
- Alice picks secret integer $a$, computes $A = g^a \bmod p$, sends $A$.
- Bob picks secret integer $b$, computes $B = g^b \bmod p$, sends $B$.
- Alice computes $B^a \bmod p = g^{ab} \bmod p$.
- Bob computes $A^b \bmod p = g^{ab} \bmod p$.
Both arrive at $K = g^{ab} \bmod p$. Eve knows $p$, $g$, $A$, and
$B$, but to find $K$ she must solve $g^a \equiv A \pmod{p}$ for $a$
— the **discrete logarithm problem**, which has no known fast
algorithm for large primes.
```{python}
import random
def dh_exchange(p, g):
"""Simulate Diffie-Hellman between Alice and Bob."""
# Each party picks a secret integer
a = random.randint(2, p - 2) # Alice's secret
b = random.randint(2, p - 2) # Bob's secret
A = pow(g, a, p) # Alice sends this
B = pow(g, b, p) # Bob sends this
shared_A = pow(B, a, p) # Alice computes
shared_B = pow(A, b, p) # Bob computes
return A, B, shared_A, shared_B
random.seed(7)
# Toy example -- real DH uses 2048-bit primes
p, g = 23, 5 # p is prime; g is a generator mod p
A, B, key_A, key_B = dh_exchange(p, g)
print(f"Public values: p={p}, g={g}")
print(f"Alice sends A = {A}")
print(f"Bob sends B = {B}")
print(f"Alice's key: {key_A}")
print(f"Bob's key: {key_B}")
print(f"Keys match: {key_A == key_B}")
```
The security of this exchange rests entirely on how hard it is to
compute discrete logarithms. For a 23-bit prime, an attacker could
try all possibilities in milliseconds. For a 2048-bit prime, no
computer on Earth can do it in a human lifetime using any known
algorithm.
```{python}
#| echo: false
from pathlib import Path; import urllib.request
_d = Path('images'); _d.mkdir(exist_ok=True)
_p = _d / 'thumb_NmM9HA2MQGI.jpg'
try:
if not _p.exists():
urllib.request.urlretrieve(
'https://img.youtube.com/vi/'
'NmM9HA2MQGI/0.jpg', _p)
except Exception:
pass
```
::: {.content-visible when-format="pdf"}
```{=latex}
\begin{center}
\begin{minipage}[c]{0.28\textwidth}
\centering
\href{https://youtu.be/NmM9HA2MQGI}{\includegraphics[width=\textwidth]{images/thumb_NmM9HA2MQGI.jpg}}
\end{minipage}%
\hspace{0.02\textwidth}%
\begin{minipage}[c]{0.28\textwidth}
\small\textbf{Computerphile}\\[3pt]
\small Secret Key Exchange (Diffie-Hellman)\\[3pt]
\small\href{https://youtu.be/NmM9HA2MQGI}{\texttt{youtu.be/NmM9HA2MQGI}}
\end{minipage}%
\hspace{0.02\textwidth}%
\begin{minipage}[c]{0.36\textwidth}
\small Dr Mike Pound explains the Diffie-Hellman key exchange using the paint-mixing analogy and the mathematics of modular exponentiation.
\end{minipage}
\end{center}
```
:::
::: {.content-visible when-format="html"}
<div style="display:flex; align-items:flex-start; margin:1em 0; gap:12px; width:100%;">
<div style="flex:0 0 200px;"><a href="https://youtu.be/NmM9HA2MQGI" target="_blank"><img src="https://img.youtube.com/vi/NmM9HA2MQGI/0.jpg" style="width:100%;display:block;" alt="Secret Key Exchange (Diffie-Hellman)"></a></div>
<div style="flex:1; font-size:0.85em;"><strong>Computerphile</strong><br>Secret Key Exchange (Diffie-Hellman)<br><a href="https://youtu.be/NmM9HA2MQGI" target="_blank" style="font-family:Consolas,monospace;">youtu.be/NmM9HA2MQGI</a></div>
<div style="flex:1; font-size:0.85em;">Dr Mike Pound explains the Diffie-Hellman key exchange using the paint-mixing analogy and the mathematics of modular exponentiation.</div>
</div>
:::
## RSA: The Lock That Anyone Can Close {#sec-crypto-rsa}
```{python}
#| echo: false
from pathlib import Path; import urllib.request
_d = Path('images'); _d.mkdir(exist_ok=True)
for _fn, _url in [
('rivest.jpg', 'https://upload.wikimedia.org/wikipedia/commons/7/79/Ronald_L_Rivest_photo.jpg'),
('shamir.jpg', 'https://upload.wikimedia.org/wikipedia/commons/9/9a/Adi_Shamir_Royal_Society.jpg'),
('adleman.jpg', 'https://upload.wikimedia.org/wikipedia/commons/a/af/Len-mankin-pic.jpg'),
]:
_p = _d / _fn
if not _p.exists():
try: urllib.request.urlretrieve(_url, _p)
except Exception: pass
```
::: {.content-visible when-format="pdf"}
```{=latex}
\begin{center}
\begin{minipage}[t]{0.27\textwidth}\centering
\IfFileExists{images/rivest.jpg}{%
\includegraphics[height=3.5cm,keepaspectratio]{images/rivest.jpg}\\[4pt]
}{}
\small\textit{Ronald Rivest}\\[-1pt]
\small\textit{(b.\ 1947)}\\[2pt]
\tiny CC BY-SA 4.0, R.~L.~Rivest
\end{minipage}%
\hspace{0.025\textwidth}%
\begin{minipage}[t]{0.27\textwidth}\centering
\IfFileExists{images/shamir.jpg}{%
\includegraphics[height=3.5cm,keepaspectratio]{images/shamir.jpg}\\[4pt]
}{}
\small\textit{Adi Shamir}\\[-1pt]
\small\textit{(b.\ 1952)}\\[2pt]
\tiny CC BY-SA 4.0, Duncan.Hull
\end{minipage}%
\hspace{0.025\textwidth}%
\begin{minipage}[t]{0.27\textwidth}\centering
\IfFileExists{images/adleman.jpg}{%
\includegraphics[height=3.5cm,keepaspectratio]{images/adleman.jpg}\\[4pt]
}{}
\small\textit{Leonard Adleman}\\[-1pt]
\small\textit{(b.\ 1945)}\\[2pt]
\tiny CC BY-SA 3.0, via Wikimedia Commons
\end{minipage}
\end{center}
```
:::
::: {.content-visible when-format="html"}
<div style="display:flex; justify-content:center; gap:24px; margin:1em 0; text-align:center; flex-wrap:wrap;">
<div style="width:110px;"><img src="images/rivest.jpg" style="width:100px; height:120px; object-fit:cover;" alt="Ronald Rivest"><div style="font-size:0.8em; margin-top:4px;"><em>Ronald Rivest (b. 1947)</em><br><span style="font-size:0.85em;">CC BY-SA 4.0, R. L. Rivest</span></div></div>
<div style="width:110px;"><img src="images/shamir.jpg" style="width:100px; height:120px; object-fit:cover;" alt="Adi Shamir"><div style="font-size:0.8em; margin-top:4px;"><em>Adi Shamir (b. 1952)</em><br><span style="font-size:0.85em;">CC BY-SA 4.0, Duncan.Hull</span></div></div>
<div style="width:110px;"><img src="images/adleman.jpg" style="width:100px; height:120px; object-fit:cover;" alt="Leonard Adleman"><div style="font-size:0.8em; margin-top:4px;"><em>Leonard Adleman (b. 1945)</em><br><span style="font-size:0.85em;">CC BY-SA 3.0, via Wikimedia Commons</span></div></div>
</div>
:::
Diffie and Hellman described the idea of **public-key cryptography**
in 1976 but did not give a complete system. One year later, Ronald
Rivest, Adi Shamir, and Leonard Adleman published the RSA
cryptosystem [@rivest1978] — still the most widely deployed
public-key system in the world.
The core idea: instead of one shared secret key, you have *two* keys.
The **public key** is like a padlock you hand out freely. Anyone can
lock a message using it. But only you, holding the **private key**,
can unlock it. You never share the private key — and the mathematics
makes it computationally infeasible to derive it from the public key.
**How RSA works:** Choose two large primes $p$ and $q$ (kept secret).
Form $n = pq$ (made public). Compute $\phi = (p-1)(q-1)$. Pick any
integer $e$ with $\gcd(e, \phi) = 1$ (made public). Find $d$ with
$ed \equiv 1 \pmod{\phi}$ using the extended Euclidean algorithm
(kept secret). Now:
$$\text{Encrypt: } c = m^e \bmod n \qquad
\text{Decrypt: } m = c^d \bmod n$$
The reason this works is Fermat's Little Theorem (from @sec-modular-fermat):
because $d$ is the modular inverse of $e$ modulo $\phi(n)$, we have
$c^d = (m^e)^d = m^{ed} \equiv m \pmod{n}$.
```{python}
from math import gcd
def rsa_keygen(p, q, e_start=65537):
"""Generate RSA public and private keys."""
n = p * q
phi = (p - 1) * (q - 1)
e = e_start
while gcd(e, phi) != 1:
e += 2
# Python 3.8+: pow(e, -1, phi) = modular inverse
d = pow(e, -1, phi)
return (n, e), (n, d)
def rsa_encrypt(m, pub):
n, e = pub
return pow(m, e, n)
def rsa_decrypt(c, priv):
n, d = priv
return pow(c, d, n)
# Toy example with deliberately small primes
p, q = 61, 53
pub, priv = rsa_keygen(p, q)
n, e = pub
_, d = priv
msg = 42
c = rsa_encrypt(msg, pub)
m2 = rsa_decrypt(c, priv)
print(f"n={n}, e={e}, d={d}")
print(f"Message: {msg}")
print(f"Encrypted: {c}")
print(f"Decrypted: {m2}")
```
We can encrypt text by treating each character as its ASCII code.
```{python}
import textwrap
text = "MATH"
ciphered = [rsa_encrypt(ord(ch), pub) for ch in text]
decoded = ''.join(
chr(rsa_decrypt(c, priv)) for c in ciphered)
print("Original: ", text)
print("Encrypted:")
# width=60 wraps long output to fit the printed page
print(textwrap.fill(str(ciphered), width=60))
print("Decrypted:", decoded)
```
The security of RSA rests on the difficulty of **integer
factorization**: given $n = pq$, it is easy to check that a given
pair of primes multiply to $n$, but there is no fast algorithm to
find those primes in the first place. For $n$ with 2048 binary digits
— today's standard — the best known algorithms would require more
computing power than exists on Earth to factor it.
```{python}
#| echo: false
from pathlib import Path; import urllib.request
_d = Path('images'); _d.mkdir(exist_ok=True)
_p = _d / 'thumb_JD72Ry60eP4.jpg'
try:
if not _p.exists():
urllib.request.urlretrieve(
'https://img.youtube.com/vi/'
'JD72Ry60eP4/0.jpg', _p)
except Exception:
pass
```
::: {.content-visible when-format="pdf"}
```{=latex}
\begin{center}
\begin{minipage}[c]{0.28\textwidth}
\centering
\href{https://youtu.be/JD72Ry60eP4}{\includegraphics[width=\textwidth]{images/thumb_JD72Ry60eP4.jpg}}
\end{minipage}%
\hspace{0.02\textwidth}%
\begin{minipage}[c]{0.28\textwidth}
\small\textbf{Computerphile}\\[3pt]
\small Prime Numbers \& RSA Encryption Algorithm\\[3pt]
\small\href{https://youtu.be/JD72Ry60eP4}{\texttt{youtu.be/JD72Ry60eP4}}
\end{minipage}%
\hspace{0.02\textwidth}%
\begin{minipage}[c]{0.36\textwidth}
\small Dr Tim Muller walks through how prime numbers are used in RSA encryption, from key generation through encrypt and decrypt.
\end{minipage}
\end{center}
```
:::
::: {.content-visible when-format="html"}
<div style="display:flex; align-items:flex-start; margin:1em 0; gap:12px; width:100%;">
<div style="flex:0 0 200px;"><a href="https://youtu.be/JD72Ry60eP4" target="_blank"><img src="https://img.youtube.com/vi/JD72Ry60eP4/0.jpg" style="width:100%;display:block;" alt="Prime Numbers and RSA Encryption Algorithm"></a></div>
<div style="flex:1; font-size:0.85em;"><strong>Computerphile</strong><br>Prime Numbers & RSA Encryption Algorithm<br><a href="https://youtu.be/JD72Ry60eP4" target="_blank" style="font-family:Consolas,monospace;">youtu.be/JD72Ry60eP4</a></div>
<div style="flex:1; font-size:0.85em;">Dr Tim Muller walks through how prime numbers are used in RSA encryption, from key generation through encrypt and decrypt.</div>
</div>
:::
## Further Research Topics {.unnumbered}
**1. ROT13 and self-inverse ciphers.**
ROT13 is Caesar with shift 13. Show that applying ROT13 twice returns
the original message. More generally, for which shifts $k$ is the
Caesar cipher a self-inverse (so encrypting twice gives back the
plaintext)? Write a program that tests all 26 shifts and find the
complete list. Why does ROT13 appear so often in online forums that
want to hide spoilers without strong encryption?
*(Problem proposed by Claude Code.)*
**2. Chi-squared key cracker.**
To crack a Caesar cipher automatically, compute the chi-squared
statistic comparing the observed ciphertext letter frequencies against
expected English frequencies for each of the 26 possible shifts. The
shift minimizing chi-squared is the most likely key. Implement this
and test it on passages of at least 200 characters. How short can the
passage be before the attack starts failing?
*(Problem proposed by Claude Code.)*
**3. Letter frequencies across languages.**
The Caesar cipher falls to frequency analysis because English letter
frequencies are uneven — but English is just one language. French,
Spanish, German, Italian, and Portuguese all use the same 26-letter
alphabet, yet each carries a different fingerprint: French text shows
a noticeably higher frequency of E (roughly 17%), while Spanish has
a more prominent A and O. Could you tell two languages apart using
only a bar chart of letter frequencies?
Download plain-text novels in at least three languages from
Project Gutenberg (gutenberg.org — use the Advanced Search to filter
by language). Strip the standard Gutenberg header and footer, filter
to only the letters A–Z (ignoring accented characters for a first
pass), count frequencies, and plot a side-by-side comparison. Which
letters are the best discriminators between languages? As a bonus,
try to build a simple classifier: given an anonymous text, can your
program guess the language from its frequency histogram alone?
**Good starting texts (search by title at gutenberg.org):**
- French: *Les Misérables* — Victor Hugo
- Spanish: *Don Quijote de la Mancha* — Miguel de Cervantes
- German: *Faust* — Johann Wolfgang von Goethe
- Italian: *La Divina Commedia* — Dante Alighieri
- Portuguese: *Os Lusíadas* — Luís de Camões
**Hint:** Gutenberg plain-text files are available at URLs of the form
`https://www.gutenberg.org/files/NNNNN/NNNNN-0.txt` once you find a
book's ID number on the site. The `urllib.request` module can download
them directly in Python.
*(Problem proposed by Claude Code.)*
**4. Cipher wheel visualization.**
Build an interactive Caesar cipher wheel using matplotlib: two
concentric rings of the alphabet, with the outer ring fixed (plaintext)
and the inner ring rotatable by a shift parameter. Animate the wheel
rotating from shift 0 to shift 25 and back. Label the alignment of A
on the inner ring to show the current key.
*(Problem proposed by Claude Code.)*
**5. Affine cipher.**
In an affine cipher, the encryption rule is $c = (a \cdot m + b)
\bmod 26$, where $m$ is the plaintext letter number (A=0, B=1, ...).
For which values of $a$ does this have a valid decryption? (Hint:
$a$ must be coprime to 26.) How many distinct affine ciphers exist?
Implement encrypt and decrypt, and show that frequency analysis still
breaks it easily.
*(Problem proposed by Claude Code.)*
**6. Polyalphabetic IoC explorer.**
For Vigenère encryption with key lengths 1 through 30, generate 50
random keys of each length, encrypt the same 1000-character English
passage with each key, and plot the mean and standard deviation of
the IoC at each key length. At what key length does the IoC reliably
drop below 0.045? How does the variance behave as key length grows?
*(Problem proposed by Claude Code.)*
**7. Kasiski test implementation.**
Given a Vigenère-encrypted text of at least 800 characters, find all
repeated three-letter substrings in the ciphertext and record the
distances between consecutive occurrences. Compute the greatest common
divisor of those distances and build a frequency table of all GCDs.
Display the results as a bar chart. Test your implementation on a
passage you encrypt yourself, then swap ciphertexts with a classmate
and try to determine their key length.
*(Problem proposed by Claude Code.)*
**8. Index of Coincidence key-length finder.**
For each candidate key length $k$ from 1 to 20, split a Vigenère
ciphertext into $k$ streams (characters at positions 0, k, 2k, ...
form the first stream; positions 1, k+1, 2k+1, ... form the second;
and so on). Compute the IoC of each stream and average them. The true
key length $k$ will show a spike because each stream is Caesar-encrypted
English. Plot average IoC versus key length and identify the peak.
*(Problem proposed by Claude Code.)*
**9. One-time pad: provably perfect secrecy.**
Shannon proved in 1949 that a one-time pad --- a key as long as the
message, used exactly once --- is perfectly secure [@shannon1949]:
every plaintext is equally likely given any ciphertext. Implement a
one-time pad using XOR on bytes. Show empirically that for any
ciphertext byte $c$ and any plaintext byte $m$, there is exactly one
key byte $k$ satisfying $m \oplus k = c$. Then demonstrate what
happens when you reuse a key: XOR two ciphertexts encrypted under
the same key to obtain the XOR of the plaintexts, and recover
intelligible words.
*(Problem proposed by Claude Code.)*
**10. Steganography capacity and PSNR.**
The **peak signal-to-noise ratio** (PSNR) measures image quality
degradation. For an 8-bit image with maximum value 255 and mean
squared error MSE, $\text{PSNR} = 10 \log_{10}(255^2 / \text{MSE})$.
Compute PSNR when hiding a message that uses 1 LSB, 2 LSBs, 3 LSBs,
and 4 LSBs of each pixel in the red channel of a test image. Plot
PSNR versus number of hidden bits per pixel. At what point does PSNR
drop below 50 dB (the threshold often cited for visually lossless
changes)? Compute the hidden capacity in ASCII characters for each
case on a 1024 × 1024 image.
*(Problem proposed by Claude Code.)*
**11. Monoalphabetic substitution cipher attack.**
In a monoalphabetic substitution cipher, each letter is replaced by
a fixed but scrambled letter (a random permutation of the alphabet).
Generate a random permutation as your secret key, encrypt a passage
of 500 characters, and then attack the ciphertext using English
single-letter frequencies, bigram frequencies (pairs like TH, HE, IN),
and common short words. Recover as much of the permutation as possible
automatically, then finish decryption by hand. How many characters
does the passage need before automatic recovery exceeds 80%?
*(Problem proposed by Claude Code.)*
**12. Diffie-Hellman with an eavesdropper.**
Simulate Alice, Bob, and Eve. Alice and Bob exchange DH values over
a public channel. Eve intercepts $p$, $g$, $A = g^a \bmod p$, and
$B = g^b \bmod p$. Implement **baby-step giant-step**: to find $a$
given $g^a \bmod p$, precompute a table of $g^j \bmod p$ for
$j = 0, 1, \ldots, \lfloor\sqrt{p}\rfloor$, then check $A \cdot
g^{-ik} \bmod p$ for $i = 0, 1, \ldots$ until a table match is
found. Time the attack for prime sizes $p \approx 10^4$, $10^6$,
$10^8$. At what size does the attack exceed one minute on your
computer?
*(Problem proposed by Claude Code.)*
**13. Primitive root finder.**
A **primitive root** modulo a prime $p$ is an integer $g$ whose
powers $g^1, g^2, \ldots, g^{p-1}$ hit every nonzero residue mod
$p$ exactly once. Write a function that finds all primitive roots for
primes up to 100. Do all primes have primitive roots? If so, how
many? Conjecture a formula for the number of primitive roots mod $p$
and test it on 20 primes.
*(Problem proposed by Claude Code.)*
**14. RSA modulus size and factoring time.**
Generate RSA key pairs with bit sizes 16, 24, 32, 40, and 48 bits
(small enough to factor). Use trial division or SymPy's `factorint`
to factor each modulus $n = pq$ and measure the elapsed time. Plot
factoring time versus bit size on a semi-log axis. Fit an exponential
model. Based on the fit, estimate how long it would take to factor a
512-bit modulus. How about 2048 bits?
*(Problem proposed by Claude Code.)*
**15. RSA broadcast attack.**
If the same message $m$ is RSA-encrypted with exponent $e = 3$ for
three different recipients with public moduli $n_1, n_2, n_3$ (all
distinct), an attacker who collects all three ciphertexts $c_1, c_2,
c_3$ can recover $m^3$ using the Chinese Remainder Theorem, then
take an integer cube root to find $m$ — with no factoring required.
Implement this attack for small messages (say, $m < 1000$) and three
distinct moduli. Why does adding random padding to $m$ before
encryption completely defeat this attack?
*(Problem proposed by Claude Code.)*
**16. Playfair cipher analysis.**
The Playfair cipher, invented by Charles Wheatstone in 1854, encrypts
letter *pairs* using a $5 \times 5$ grid of letters. Because it acts
on pairs rather than single letters, simple frequency analysis fails.
Implement Playfair encryption and decryption. Encrypt a 500-character
passage, then compute the frequency distribution of all 600+ possible
digraphs in the ciphertext. Compare this digraph frequency table to
the digraph frequencies in English (TH, HE, IN are common) and to
the digraph frequencies in the original Playfair plaintext. How much
harder is Playfair to crack than Caesar?
*(Problem proposed by Claude Code.)*
**17. Vigenère full break.**
Given a Vigenère ciphertext whose key length $k$ you have already
determined (using the IoC method from topic 7), split the text into
$k$ streams and apply the chi-squared frequency attack (topic 2) to
each stream independently. Each stream is just Caesar-encrypted
English, so the chi-squared minimizer gives one letter of the key.
Assemble the full key and decrypt. Test on a passage of your choice,
swap encrypted texts with a classmate, and compete to break their
key first.
*(Problem proposed by Claude Code.)*
**18. Visual cryptography.**
Naor and Shamir (1994) described a scheme where a secret black-and-white
image is split into two "shares" that each look like random noise.
When both shares are overlaid (OR-combined pixel by pixel), the
original image appears. Implement a $(2,2)$ visual cryptography
scheme for a small binary image of your choosing (a letter, a simple
shape). Verify that neither share alone reveals anything about the
secret, and that their union recovers it exactly.
*(Problem proposed by Claude Code.)*
**19. Diffie-Hellman key exchange.**
Two parties agree publicly on a large prime $p$ and a primitive root
$g$ (the *generator*). Alice picks a secret integer $a$ and sends
$A = g^a \bmod p$; Bob picks secret $b$ and sends $B = g^b \bmod p$.
Both independently compute the shared secret $K = g^{ab} \bmod p$
(Alice computes $B^a \bmod p$, Bob computes $A^b \bmod p$) ---
without ever transmitting $K$ [@diffie1976new]. Implement this
protocol in Python using `pow(base, exp, mod)` and verify that Alice
and Bob agree. An eavesdropper who sees $p$, $g$, $A$, and $B$ must
solve $g^a \equiv A \pmod p$ for $a$ --- the **discrete logarithm
problem**, believed infeasible for large $p$. Using the baby-step
giant-step algorithm from topic 11, demonstrate that the protocol is
breakable when $p$ is small (say, 10 digits) and estimate how long
the attack would take for a 100-digit prime.
*(Problem proposed by Claude Code.)*
**20. RSA in 20 lines.**
RSA encryption [@rivest1978] selects primes $p$ and $q$, sets
$n = pq$, picks $e$ coprime to $(p-1)(q-1)$, and encrypts message
$m$ as $c = m^e \bmod n$. Decryption finds $d$ with $ed \equiv 1
\pmod{(p-1)(q-1)}$ (use the extended Euclidean algorithm), then
recovers $m = c^d \bmod n$. Fermat's Little Theorem is the reason
this works: prove that $c^d \equiv m \pmod n$. Implement a toy RSA
scheme with small primes (say $p = 61$, $q = 53$). Encode each
letter of a short message as its ASCII value, encrypt each character,
decrypt, and recover the original text. Verify that `pow(c, d, n)`
is essential by explaining what happens to `(c**d) % n` for realistic
2048-bit key sizes.
*(Problem proposed by Claude Code.)*
**21. Shamir's secret sharing.**
Adi Shamir showed in 1979 that a secret integer $s$ can be split into
$n$ shares so that any $k$ shares reconstruct $s$ exactly, while any
$k - 1$ shares reveal *nothing* about $s$ [@shamir1979]. The scheme
works over modular arithmetic: choose a random degree-$(k-1)$
polynomial $f(x) = s + a_1 x + \cdots + a_{k-1} x^{k-1} \pmod p$
where $p$ is a prime larger than $s$ and larger than $n$. Distribute
share $i$ as the pair $(i,\; f(i) \bmod p)$ for $i = 1, \ldots, n$.
Any $k$ shares determine $f$ by Lagrange interpolation mod $p$, so
the secret $s = f(0)$ is recovered; any $k - 1$ shares are consistent
with every possible value of $s$. Implement a $(3, 5)$ threshold
scheme in Python: split the secret 42 with a large prime modulus,
generate five shares, and verify that any three shares reconstruct
42 while any two shares can be extended to match *any* secret value.
Why must $p$ be prime for the Lagrange formula to work over the
integers mod $p$?
*(Problem proposed by Claude Code.)*